SWIGGY — End To End Data Engineering Project

Discover how food aggregators and quick-commerce platforms like Swiggy leverage the Snowflake to power their data pipelines! This hands-on tutorial starts with a high-level food order process flow, explores the OLTP source ER diagram for data analysis, and explains the 3-layer data warehouse architecture.
Watch as we transform data flow requirements into implementation, create fact and dimension tables, and build an interactive Streamlit dashboard. Perfect for beginners or those curious about executing end-to-end data projects in Snowflake, this real life end to end data project walkthrough will demystify the process 🪜 step by step 🪜 using snowflake cloud data platform.
Design Considerations 🏗️
Explore the critical decisions behind crafting the data model and structuring the overall project architecture tailored for a food aggregator’s data pipeline.
End To End Data Flow
Follow the journey of data from loading and curation to transformation within Snowflake. Gain insights into the step-by-step process for ensuring data quality and integrity while leveraging Snowflake to maximize efficiency and streamline the pipeline.
Once you complete this end to end real life food aggregator based data engineering project (ETL or ELT) using snowflake, you would be able answer of following questions
- 🤔 How to load data using snowflake’s snowsight data loading feature without any tool dependency?
- 🤔 How to load delta data set and let is go through the data pipeline? 🤔 How to use $ notation to query stage file?
- 🤔 How to run copy command to load CSV files into tables?
- 🤔 How to design different layers & fact/dimension tables?
- 🤔 How to see the KPI and data insight using Streamlit?
High Level Data Flow Architecture
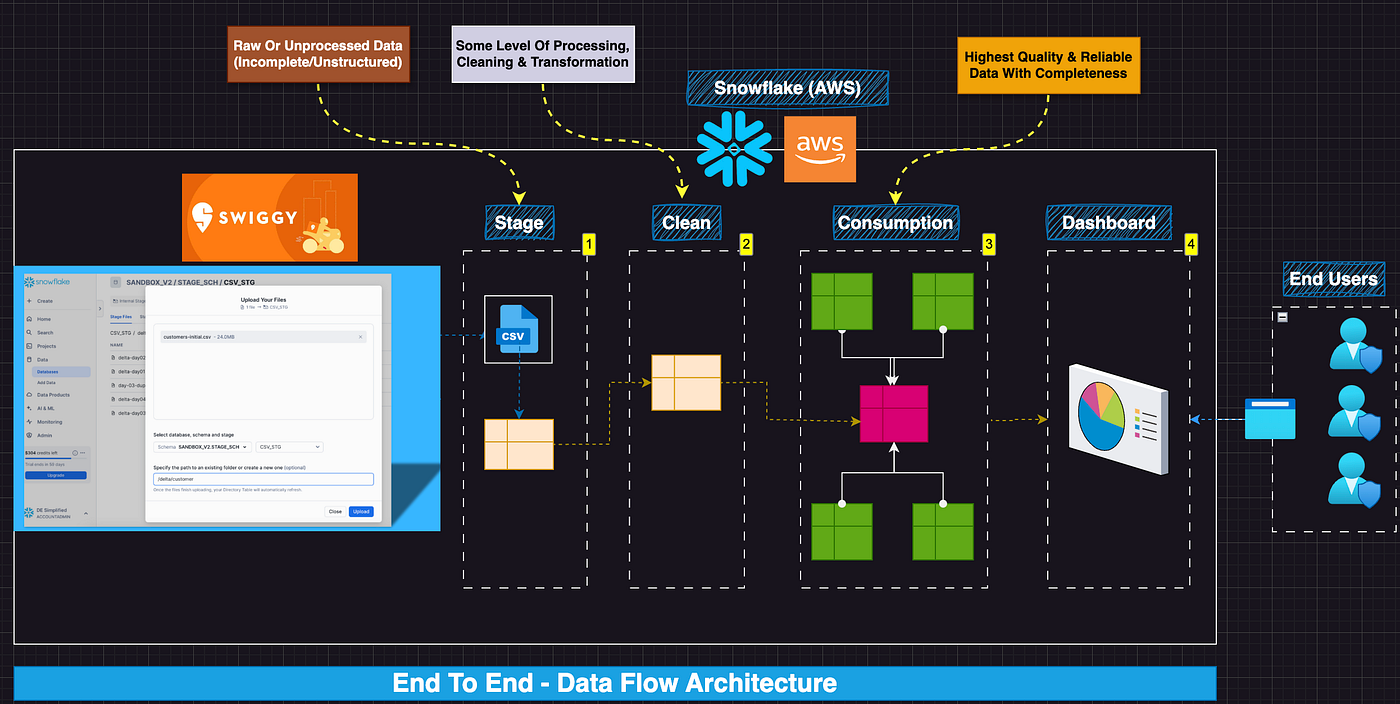
Create Database, Schema & Common Object
-- use sysadmin role.
use role sysadmin;
-- create a warehouse if not exist
create warehouse if not exists adhoc_wh
comment = 'This is the adhoc-wh'
warehouse_size = 'x-small'
auto_resume = true
auto_suspend = 60
enable_query_acceleration = false
warehouse_type = 'standard'
min_cluster_count = 1
max_cluster_count = 1
scaling_policy = 'standard'
initially_suspended = true;
-- create development database/schema if does not exist
create database if not exists sandbox;
use database sandbox;
create schema if not exists stage_sch;
create schema if not exists clean_sch;
create schema if not exists consumption_sch;
create schema if not exists common;
use schema stage_sch;
-- create file format to process the CSV file
create file format if not exists stage_sch.csv_file_format
type = 'csv'
compression = 'auto'
field_delimiter = ','
record_delimiter = '\n'
skip_header = 1
field_optionally_enclosed_by = '\042'
null_if = ('\\N');
create stage stage_sch.csv_stg
directory = ( enable = true )
comment = 'this is the snowflake internal stage';
create or replace tag
common.pii_policy_tag
allowed_values 'PII','PRICE','SENSITIVE','EMAIL'
comment = 'This is PII policy tag object';
create or replace masking policy
common.pii_masking_policy as (pii_text string)
returns string ->
to_varchar('** PII **');
create or replace masking policy
common.email_masking_policy as (email_text string)
returns string ->
to_varchar('** EAMIL **');
create or replace masking policy
common.phone_masking_policy as (phone string)
returns string ->
to_varchar('** Phone **');Sample CSV Files
Here is the sample data setup that must be loaded before runing SQL scripts.
Location Dimension — SQL Script

use role sysadmin;
use schema sandbox.stage_sch;
create table stage_sch.location (
locationid text,
city text,
state text,
zipcode text,
activeflag text,
createddate text,
modifieddate text,
-- audit columns for tracking & debugging
_stg_file_name text,
_stg_file_load_ts timestamp,
_stg_file_md5 text,
_copy_data_ts timestamp default current_timestamp
)
comment = 'This is the location stage/raw table where data will be copied from internal stage using copy command. This is as-is data represetation from the source location. All the columns are text data type except the audit columns that are added for traceability.'
;
create or replace stream stage_sch.location_stm
on table stage_sch.location
append_only = true
comment = 'this is the append-only stream object on location table that gets delta data based on changes';
select * from stage_sch.location;
copy into stage_sch.location (locationid, city, state, zipcode, activeflag,
createddate, modifieddate, _stg_file_name,
_stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as locationid,
t.$2::text as city,
t.$3::text as state,
t.$4::text as zipcode,
t.$5::text as activeflag,
t.$6::text as createddate,
t.$7::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/initial/location t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
select *
from table(information_schema.copy_history(table_name=>'LOCATION', start_time=> dateadd(hours, -1, current_timestamp())));
select * from stage_sch.location;
select * from stage_sch.location_stm;
use schema clean_sch;
-- Level 2
create or replace table clean_sch.restaurant_location (
restaurant_location_sk number autoincrement primary key,
location_id number not null unique,
city string(100) not null,
state string(100) not null,
state_code string(2) not null,
is_union_territory boolean not null default false,
capital_city_flag boolean not null default false,
city_tier text(6),
zip_code string(10) not null,
active_flag string(10) not null,
created_ts timestamp_tz not null,
modified_ts timestamp_tz,
-- additional audit columns
_stg_file_name string,
_stg_file_load_ts timestamp_ntz,
_stg_file_md5 string,
_copy_data_ts timestamp_ntz default current_timestamp
)
comment = 'Location entity under clean schema with appropriate data type under clean schema layer, data is populated using merge statement from the stage layer location table. This table does not support SCD2';
create or replace stream clean_sch.restaurant_location_stm
on table clean_sch.restaurant_location
comment = 'this is a standard stream object on the location table to track insert, update, and delete changes';
MERGE INTO clean_sch.restaurant_location AS target
USING (
SELECT
CAST(LocationID AS NUMBER) AS Location_ID,
CAST(City AS STRING) AS City,
CASE
WHEN CAST(State AS STRING) = 'Delhi' THEN 'New Delhi'
ELSE CAST(State AS STRING)
END AS State,
-- State Code Mapping
CASE
WHEN State = 'Delhi' THEN 'DL'
WHEN State = 'Maharashtra' THEN 'MH'
WHEN State = 'Uttar Pradesh' THEN 'UP'
WHEN State = 'Gujarat' THEN 'GJ'
WHEN State = 'Rajasthan' THEN 'RJ'
WHEN State = 'Kerala' THEN 'KL'
WHEN State = 'Punjab' THEN 'PB'
WHEN State = 'Karnataka' THEN 'KA'
WHEN State = 'Madhya Pradesh' THEN 'MP'
WHEN State = 'Odisha' THEN 'OR'
WHEN State = 'Chandigarh' THEN 'CH'
WHEN State = 'West Bengal' THEN 'WB'
WHEN State = 'Sikkim' THEN 'SK'
WHEN State = 'Andhra Pradesh' THEN 'AP'
WHEN State = 'Assam' THEN 'AS'
WHEN State = 'Jammu and Kashmir' THEN 'JK'
WHEN State = 'Puducherry' THEN 'PY'
WHEN State = 'Uttarakhand' THEN 'UK'
WHEN State = 'Himachal Pradesh' THEN 'HP'
WHEN State = 'Tamil Nadu' THEN 'TN'
WHEN State = 'Goa' THEN 'GA'
WHEN State = 'Telangana' THEN 'TG'
WHEN State = 'Chhattisgarh' THEN 'CG'
WHEN State = 'Jharkhand' THEN 'JH'
WHEN State = 'Bihar' THEN 'BR'
ELSE NULL
END AS state_code,
CASE
WHEN State IN ('Delhi', 'Chandigarh', 'Puducherry', 'Jammu and Kashmir') THEN 'Y'
ELSE 'N'
END AS is_union_territory,
CASE
WHEN (State = 'Delhi' AND City = 'New Delhi') THEN TRUE
WHEN (State = 'Maharashtra' AND City = 'Mumbai') THEN TRUE
-- Other conditions for capital cities
ELSE FALSE
END AS capital_city_flag,
CASE
WHEN City IN ('Mumbai', 'Delhi', 'Bengaluru', 'Hyderabad', 'Chennai', 'Kolkata', 'Pune', 'Ahmedabad') THEN 'Tier-1'
WHEN City IN ('Jaipur', 'Lucknow', 'Kanpur', 'Nagpur', 'Indore', 'Bhopal', 'Patna', 'Vadodara', 'Coimbatore',
'Ludhiana', 'Agra', 'Nashik', 'Ranchi', 'Meerut', 'Raipur', 'Guwahati', 'Chandigarh') THEN 'Tier-2'
ELSE 'Tier-3'
END AS city_tier,
CAST(ZipCode AS STRING) AS Zip_Code,
CAST(ActiveFlag AS STRING) AS Active_Flag,
TO_TIMESTAMP_TZ(CreatedDate, 'YYYY-MM-DD HH24:MI:SS') AS created_ts,
TO_TIMESTAMP_TZ(ModifiedDate, 'YYYY-MM-DD HH24:MI:SS') AS modified_ts,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
CURRENT_TIMESTAMP AS _copy_data_ts
FROM stage_sch.location_stm
) AS source
ON target.Location_ID = source.Location_ID
WHEN MATCHED AND (
target.City != source.City OR
target.State != source.State OR
target.state_code != source.state_code OR
target.is_union_territory != source.is_union_territory OR
target.capital_city_flag != source.capital_city_flag OR
target.city_tier != source.city_tier OR
target.Zip_Code != source.Zip_Code OR
target.Active_Flag != source.Active_Flag OR
target.modified_ts != source.modified_ts
) THEN
UPDATE SET
target.City = source.City,
target.State = source.State,
target.state_code = source.state_code,
target.is_union_territory = source.is_union_territory,
target.capital_city_flag = source.capital_city_flag,
target.city_tier = source.city_tier,
target.Zip_Code = source.Zip_Code,
target.Active_Flag = source.Active_Flag,
target.modified_ts = source.modified_ts,
target._stg_file_name = source._stg_file_name,
target._stg_file_load_ts = source._stg_file_load_ts,
target._stg_file_md5 = source._stg_file_md5,
target._copy_data_ts = source._copy_data_ts
WHEN NOT MATCHED THEN
INSERT (
Location_ID,
City,
State,
state_code,
is_union_territory,
capital_city_flag,
city_tier,
Zip_Code,
Active_Flag,
created_ts,
modified_ts,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
_copy_data_ts
)
VALUES (
source.Location_ID,
source.City,
source.State,
source.state_code,
source.is_union_territory,
source.capital_city_flag,
source.city_tier,
source.Zip_Code,
source.Active_Flag,
source.created_ts,
source.modified_ts,
source._stg_file_name,
source._stg_file_load_ts,
source._stg_file_md5,
source._copy_data_ts
);
create or replace table consumption_sch.restaurant_location_dim (
restaurant_location_hk NUMBER primary key, -- hash key for the dimension
location_id number(38,0) not null, -- business key
city varchar(100) not null, -- city
state varchar(100) not null, -- state
state_code varchar(2) not null, -- state code
is_union_territory boolean not null default false, -- union territory flag
capital_city_flag boolean not null default false, -- capital city flag
city_tier varchar(6), -- city tier
zip_code varchar(10) not null, -- zip code
active_flag varchar(10) not null, -- active flag (indicating current record)
eff_start_dt timestamp_tz(9) not null, -- effective start date for scd2
eff_end_dt timestamp_tz(9), -- effective end date for scd2
current_flag boolean not null default true -- indicator of the current record
)
comment = 'Dimension table for restaurant location with scd2 (slowly changing dimension) enabled and hashkey as surrogate key';
MERGE INTO
CONSUMPTION_SCH.RESTAURANT_LOCATION_DIM AS target
USING
CLEAN_SCH.RESTAURANT_LOCATION_STM AS source
ON
target.LOCATION_ID = source.LOCATION_ID and
target.ACTIVE_FLAG = source.ACTIVE_FLAG
WHEN MATCHED
AND source.METADATA$ACTION = 'DELETE' and source.METADATA$ISUPDATE = 'TRUE' THEN
-- Update the existing record to close its validity period
UPDATE SET
target.EFF_END_DT = CURRENT_TIMESTAMP(),
target.CURRENT_FLAG = FALSE
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT' and source.METADATA$ISUPDATE = 'TRUE'
THEN
-- Insert new record with current data and new effective start date
INSERT (
RESTAURANT_LOCATION_HK,
LOCATION_ID,
CITY,
STATE,
STATE_CODE,
IS_UNION_TERRITORY,
CAPITAL_CITY_FLAG,
CITY_TIER,
ZIP_CODE,
ACTIVE_FLAG,
EFF_START_DT,
EFF_END_DT,
CURRENT_FLAG
)
VALUES (
hash(SHA1_hex(CONCAT(source.CITY, source.STATE, source.STATE_CODE, source.ZIP_CODE))),
source.LOCATION_ID,
source.CITY,
source.STATE,
source.STATE_CODE,
source.IS_UNION_TERRITORY,
source.CAPITAL_CITY_FLAG,
source.CITY_TIER,
source.ZIP_CODE,
source.ACTIVE_FLAG,
CURRENT_TIMESTAMP(),
NULL,
TRUE
)
WHEN NOT MATCHED AND
source.METADATA$ACTION = 'INSERT' and source.METADATA$ISUPDATE = 'FALSE' THEN
-- Insert new record with current data and new effective start date
INSERT (
RESTAURANT_LOCATION_HK,
LOCATION_ID,
CITY,
STATE,
STATE_CODE,
IS_UNION_TERRITORY,
CAPITAL_CITY_FLAG,
CITY_TIER,
ZIP_CODE,
ACTIVE_FLAG,
EFF_START_DT,
EFF_END_DT,
CURRENT_FLAG
)
VALUES (
hash(SHA1_hex(CONCAT(source.CITY, source.STATE, source.STATE_CODE, source.ZIP_CODE))),
source.LOCATION_ID,
source.CITY,
source.STATE,
source.STATE_CODE,
source.IS_UNION_TERRITORY,
source.CAPITAL_CITY_FLAG,
source.CITY_TIER,
source.ZIP_CODE,
source.ACTIVE_FLAG,
CURRENT_TIMESTAMP(),
NULL,
TRUE
);
-- Part-2
copy into stage_sch.location (locationid, city, state, zipcode, activeflag,
createddate, modifieddate, _stg_file_name,
_stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as locationid,
t.$2::text as city,
t.$3::text as state,
t.$4::text as zipcode,
t.$5::text as activeflag,
t.$6::text as createddate,
t.$7::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/delta/location/delta-day02-2rows-update.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
Restaurant Dimension — SQL Script

-- change context
use role sysadmin;
use database sandbox;
use schema stage_sch;
use warehouse adhoc_wh;
-- create restaurant table under stage location, with all text value + audit column for copy command
create or replace table stage_sch.restaurant (
restaurantid text,
name text , -- restaurant name, required field
cuisinetype text, -- type of cuisine offered
pricing_for_2 text, -- pricing for two people as text
restaurant_phone text WITH TAG (common.pii_policy_tag = 'SENSITIVE'), -- phone number as text
operatinghours text, -- restaurant operating hours
locationid text , -- location id, default as text
activeflag text , -- active status
openstatus text , -- open status
locality text, -- locality as text
restaurant_address text, -- address as text
latitude text, -- latitude as text for precision
longitude text, -- longitude as text for precision
createddate text, -- record creation date
modifieddate text, -- last modified date
-- audit columns for debugging
_stg_file_name text,
_stg_file_load_ts timestamp,
_stg_file_md5 text,
_copy_data_ts timestamp default current_timestamp
)
comment = 'This is the restaurant stage/raw table where data will be copied from internal stage using copy command. This is as-is data represetation from the source location. All the columns are text data type except the audit columns that are added for traceability.'
;
-- Stream object to capture the changes.
create or replace stream stage_sch.restaurant_stm
on table stage_sch.restaurant
append_only = true
comment = 'This is the append-only stream object on restaurant table that only gets delta data';
-- run copy command to load the data into stage-restaurant table.
copy into stage_sch.restaurant (restaurantid, name, cuisinetype, pricing_for_2, restaurant_phone,
operatinghours, locationid, activeflag, openstatus,
locality, restaurant_address, latitude, longitude,
createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as restaurantid, -- restaurantid as the first column
t.$2::text as name,
t.$3::text as cuisinetype,
t.$4::text as pricing_for_2,
t.$5::text as restaurant_phone,
t.$6::text as operatinghours,
t.$7::text as locationid,
t.$8::text as activeflag,
t.$9::text as openstatus,
t.$10::text as locality,
t.$11::text as restaurant_address,
t.$12::text as latitude,
t.$13::text as longitude,
t.$14::text as createddate,
t.$15::text as modifieddate,
-- audit columns for tracking & debugging
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp() as _copy_data_ts
from @stage_sch.csv_stg/initial/restaurant/restaurant-delhi+NCR.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
-- the restaurant table where data types are defined.
create or replace table clean_sch.restaurant (
restaurant_sk number autoincrement primary key, -- primary key with auto-increment
restaurant_id number unique, -- restaurant id without auto-increment
name string(100) not null, -- restaurant name, required field
cuisine_type string, -- type of cuisine offered
pricing_for_two number(10, 2), -- pricing for two people, up to 10 digits with 2 decimal places
restaurant_phone string(15) WITH TAG (common.pii_policy_tag = 'SENSITIVE'), -- phone number, supports 10-digit or international format
operating_hours string(100), -- restaurant operating hours
location_id_fk number, -- reference id for location, defaulted to 1
active_flag string(10), -- indicates if the restaurant is active
open_status string(10), -- indicates if the restaurant is currently open
locality string(100), -- locality of the restaurant
restaurant_address string, -- address of the restaurant, supports longer text
latitude number(9, 6), -- latitude with 6 decimal places for precision
longitude number(9, 6), -- longitude with 6 decimal places for precision
created_dt timestamp_tz, -- record creation date
modified_dt timestamp_tz, -- last modified date, allows null if not modified
-- additional audit columns
_stg_file_name string, -- file name for audit
_stg_file_load_ts timestamp_ntz, -- file load timestamp for audit
_stg_file_md5 string, -- md5 hash for file content for audit
_copy_data_ts timestamp_ntz default current_timestamp -- timestamp when data is copied, defaults to current timestamp
)
comment = 'Restaurant entity under clean schema with appropriate data type under clean schema layer, data is populated using merge statement from the stage layer location table. This table does not support SCD2';
create or replace stream clean_sch.restaurant_stm
on table clean_sch.restaurant
comment = 'This is a standard stream object on the clean restaurant table to track insert, update, and delete changes';
-- following is the insert statement..
insert into clean_sch.restaurant (
restaurant_id,
name,
cuisine_type,
pricing_for_two,
restaurant_phone,
operating_hours,
location_id_fk,
active_flag,
open_status,
locality,
restaurant_address,
latitude,
longitude,
created_dt,
modified_dt,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5
)
select
try_cast(restaurantid as number) as restaurant_id,
try_cast(name as string) as name,
try_cast(cuisinetype as string) as cuisine_type,
try_cast(pricing_for_2 as number(10, 2)) as pricing_for_two,
try_cast(restaurant_phone as string) as restaurant_phone,
try_cast(operatinghours as string) as operating_hours,
try_cast(locationid as number) as location_id_fk,
try_cast(activeflag as string) as active_flag,
try_cast(openstatus as string) as open_status,
try_cast(locality as string) as locality,
try_cast(restaurant_address as string) as restaurant_address,
try_cast(latitude as number(9, 6)) as latitude,
try_cast(longitude as number(9, 6)) as longitude,
try_to_timestamp_ntz(createddate, 'YYYY-MM-DD HH24:MI:SS.FF9') as created_dt,
try_to_timestamp_ntz(modifieddate, 'YYYY-MM-DD HH24:MI:SS.FF9') as modified_dt,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5
from
stage_sch.restaurant;
-- here is the merge statement
MERGE INTO clean_sch.restaurant AS target
USING (
SELECT
try_cast(restaurantid AS number) AS restaurant_id,
try_cast(name AS string) AS name,
try_cast(cuisinetype AS string) AS cuisine_type,
try_cast(pricing_for_2 AS number(10, 2)) AS pricing_for_two,
try_cast(restaurant_phone AS string) AS restaurant_phone,
try_cast(operatinghours AS string) AS operating_hours,
try_cast(locationid AS number) AS location_id_fk,
try_cast(activeflag AS string) AS active_flag,
try_cast(openstatus AS string) AS open_status,
try_cast(locality AS string) AS locality,
try_cast(restaurant_address AS string) AS restaurant_address,
try_cast(latitude AS number(9, 6)) AS latitude,
try_cast(longitude AS number(9, 6)) AS longitude,
try_to_timestamp_ntz(createddate, 'YYYY-MM-DD HH24:MI:SS.FF9') AS created_dt,
try_to_timestamp_ntz(modifieddate, 'YYYY-MM-DD HH24:MI:SS.FF9') AS modified_dt,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5
FROM
stage_sch.restaurant_stm
) AS source
ON target.restaurant_id = source.restaurant_id
WHEN MATCHED THEN
UPDATE SET
target.name = source.name,
target.cuisine_type = source.cuisine_type,
target.pricing_for_two = source.pricing_for_two,
target.restaurant_phone = source.restaurant_phone,
target.operating_hours = source.operating_hours,
target.location_id_fk = source.location_id_fk,
target.active_flag = source.active_flag,
target.open_status = source.open_status,
target.locality = source.locality,
target.restaurant_address = source.restaurant_address,
target.latitude = source.latitude,
target.longitude = source.longitude,
target.created_dt = source.created_dt,
target.modified_dt = source.modified_dt,
target._stg_file_name = source._stg_file_name,
target._stg_file_load_ts = source._stg_file_load_ts,
target._stg_file_md5 = source._stg_file_md5
WHEN NOT MATCHED THEN
INSERT (
restaurant_id,
name,
cuisine_type,
pricing_for_two,
restaurant_phone,
operating_hours,
location_id_fk,
active_flag,
open_status,
locality,
restaurant_address,
latitude,
longitude,
created_dt,
modified_dt,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5
)
VALUES (
source.restaurant_id,
source.name,
source.cuisine_type,
source.pricing_for_two,
source.restaurant_phone,
source.operating_hours,
source.location_id_fk,
source.active_flag,
source.open_status,
source.locality,
source.restaurant_address,
source.latitude,
source.longitude,
source.created_dt,
source.modified_dt,
source._stg_file_name,
source._stg_file_load_ts,
source._stg_file_md5
);
-- now define dim table for restaurant.
CREATE OR REPLACE TABLE CONSUMPTION_SCH.RESTAURANT_DIM (
RESTAURANT_HK NUMBER primary key, -- Hash key for the restaurant location
RESTAURANT_ID NUMBER, -- Restaurant ID without auto-increment
NAME STRING(100), -- Restaurant name
CUISINE_TYPE STRING, -- Type of cuisine offered
PRICING_FOR_TWO NUMBER(10, 2), -- Pricing for two people
RESTAURANT_PHONE STRING(15) WITH TAG (common.pii_policy_tag = 'SENSITIVE'), -- Restaurant phone number
OPERATING_HOURS STRING(100), -- Restaurant operating hours
LOCATION_ID_FK NUMBER, -- Foreign key reference to location
ACTIVE_FLAG STRING(10), -- Indicates if the restaurant is active
OPEN_STATUS STRING(10), -- Indicates if the restaurant is currently open
LOCALITY STRING(100), -- Locality of the restaurant
RESTAURANT_ADDRESS STRING, -- Full address of the restaurant
LATITUDE NUMBER(9, 6), -- Latitude for the restaurant's location
LONGITUDE NUMBER(9, 6), -- Longitude for the restaurant's location
EFF_START_DATE TIMESTAMP_TZ, -- Effective start date for the record
EFF_END_DATE TIMESTAMP_TZ, -- Effective end date for the record (NULL if active)
IS_CURRENT BOOLEAN -- Indicates whether the record is the current version
)
COMMENT = 'Dimensional table for Restaurant entity with hash keys and SCD enabled.';
-- how many changes are available.
select count(*) from CLEAN_SCH.RESTAURANT_STM;
-- merge statement
MERGE INTO
CONSUMPTION_SCH.RESTAURANT_DIM AS target
USING
CLEAN_SCH.RESTAURANT_STM AS source
ON
target.RESTAURANT_ID = source.RESTAURANT_ID AND
target.NAME = source.NAME AND
target.CUISINE_TYPE = source.CUISINE_TYPE AND
target.PRICING_FOR_TWO = source.PRICING_FOR_TWO AND
target.RESTAURANT_PHONE = source.RESTAURANT_PHONE AND
target.OPERATING_HOURS = source.OPERATING_HOURS AND
target.LOCATION_ID_FK = source.LOCATION_ID_FK AND
target.ACTIVE_FLAG = source.ACTIVE_FLAG AND
target.OPEN_STATUS = source.OPEN_STATUS AND
target.LOCALITY = source.LOCALITY AND
target.RESTAURANT_ADDRESS = source.RESTAURANT_ADDRESS AND
target.LATITUDE = source.LATITUDE AND
target.LONGITUDE = source.LONGITUDE
WHEN MATCHED
AND source.METADATA$ACTION = 'DELETE' AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Update the existing record to close its validity period
UPDATE SET
target.EFF_END_DATE = CURRENT_TIMESTAMP(),
target.IS_CURRENT = FALSE
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT' AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Insert new record with current data and new effective start date
INSERT (
RESTAURANT_HK,
RESTAURANT_ID,
NAME,
CUISINE_TYPE,
PRICING_FOR_TWO,
RESTAURANT_PHONE,
OPERATING_HOURS,
LOCATION_ID_FK,
ACTIVE_FLAG,
OPEN_STATUS,
LOCALITY,
RESTAURANT_ADDRESS,
LATITUDE,
LONGITUDE,
EFF_START_DATE,
EFF_END_DATE,
IS_CURRENT
)
VALUES (
hash(SHA1_hex(CONCAT(source.RESTAURANT_ID, source.NAME, source.CUISINE_TYPE,
source.PRICING_FOR_TWO, source.RESTAURANT_PHONE, source.OPERATING_HOURS,
source.LOCATION_ID_FK, source.ACTIVE_FLAG, source.OPEN_STATUS, source.LOCALITY,
source.RESTAURANT_ADDRESS, source.LATITUDE, source.LONGITUDE))),
source.RESTAURANT_ID,
source.NAME,
source.CUISINE_TYPE,
source.PRICING_FOR_TWO,
source.RESTAURANT_PHONE,
source.OPERATING_HOURS,
source.LOCATION_ID_FK,
source.ACTIVE_FLAG,
source.OPEN_STATUS,
source.LOCALITY,
source.RESTAURANT_ADDRESS,
source.LATITUDE,
source.LONGITUDE,
CURRENT_TIMESTAMP(),
NULL,
TRUE
)
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT' AND source.METADATA$ISUPDATE = 'FALSE' THEN
-- Insert new record with current data and new effective start date
INSERT (
RESTAURANT_HK,
RESTAURANT_ID,
NAME,
CUISINE_TYPE,
PRICING_FOR_TWO,
RESTAURANT_PHONE,
OPERATING_HOURS,
LOCATION_ID_FK,
ACTIVE_FLAG,
OPEN_STATUS,
LOCALITY,
RESTAURANT_ADDRESS,
LATITUDE,
LONGITUDE,
EFF_START_DATE,
EFF_END_DATE,
IS_CURRENT
)
VALUES (
hash(SHA1_hex(CONCAT(source.RESTAURANT_ID, source.NAME, source.CUISINE_TYPE,
source.PRICING_FOR_TWO, source.RESTAURANT_PHONE, source.OPERATING_HOURS,
source.LOCATION_ID_FK, source.ACTIVE_FLAG, source.OPEN_STATUS, source.LOCALITY,
source.RESTAURANT_ADDRESS, source.LATITUDE, source.LONGITUDE))),
source.RESTAURANT_ID,
source.NAME,
source.CUISINE_TYPE,
source.PRICING_FOR_TWO,
source.RESTAURANT_PHONE,
source.OPERATING_HOURS,
source.LOCATION_ID_FK,
source.ACTIVE_FLAG,
source.OPEN_STATUS,
source.LOCALITY,
source.RESTAURANT_ADDRESS,
source.LATITUDE,
source.LONGITUDE,
CURRENT_TIMESTAMP(),
NULL,
TRUE
);
-- load the delta data
list @stage_sch.csv_stg/daily/restaurant/;
copy into stage_sch.restaurant (restaurantid, name, cuisinetype, pricing_for_2, restaurant_phone,
operatinghours, locationid, activeflag, openstatus,
locality, restaurant_address, latitude, longitude,
createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as restaurantid, -- restaurantid as the first column
t.$2::text as name,
t.$3::text as cuisinetype,
t.$4::text as pricing_for_2,
t.$5::text as restaurant_phone,
t.$6::text as operatinghours,
t.$7::text as locationid,
t.$8::text as activeflag,
t.$9::text as openstatus,
t.$10::text as locality,
t.$11::text as restaurant_address,
t.$12::text as latitude,
t.$13::text as longitude,
t.$14::text as createddate,
t.$15::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp() as _copy_data_ts
from @stage_sch.csv_stg/daily/restaurant/day-02-upsert-restaurant-delhi+NCR.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
// ------------------------------------------------
// Part -2 loading the delta data
list @stage_sch.csv_stg/delta/restaurant/;
copy into stage_sch.restaurant (restaurantid, name, cuisinetype, pricing_for_2, restaurant_phone,
operatinghours, locationid, activeflag, openstatus,
locality, restaurant_address, latitude, longitude,
createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as restaurantid, -- restaurantid as the first column
t.$2::text as name,
t.$3::text as cuisinetype,
t.$4::text as pricing_for_2,
t.$5::text as restaurant_phone,
t.$6::text as operatinghours,
t.$7::text as locationid,
t.$8::text as activeflag,
t.$9::text as openstatus,
t.$10::text as locality,
t.$11::text as restaurant_address,
t.$12::text as latitude,
t.$13::text as longitude,
t.$14::text as createddate,
t.$15::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp() as _copy_data_ts
from @stage_sch.csv_stg/delta/restaurant/day-02-upsert-restaurant-delhi+NCR.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
select *
from table(information_schema.copy_history(table_name=>'RESTAURANT', start_time=> dateadd(hours, -1, current_timestamp())));Customer Dimension — SQL Script

use role sysadmin;
use database sandbox;
use schema stage_sch;
use warehouse adhoc_wh;
-- create restaurant table under stage, with all text value + audit column for copy command
create or replace table stage_sch.customer (
customerid text, -- primary key as text
name text, -- name as text
mobile text WITH TAG (common.pii_policy_tag = 'PII'), -- mobile number as text
email text WITH TAG (common.pii_policy_tag = 'EMAIL'), -- email as text
loginbyusing text, -- login method as text
gender text WITH TAG (common.pii_policy_tag = 'PII'), -- gender as text
dob text WITH TAG (common.pii_policy_tag = 'PII'), -- date of birth as text
anniversary text, -- anniversary as text
preferences text, -- preferences as text
createddate text, -- created date as text
modifieddate text, -- modified date as text
-- audit columns with appropriate data types
_stg_file_name text,
_stg_file_load_ts timestamp,
_stg_file_md5 text,
_copy_data_ts timestamp default current_timestamp
)
comment = 'This is the customer stage/raw table where data will be copied from internal stage using copy command. This is as-is data represetation from the source location. All the columns are text data type except the audit columns that are added for traceability.';
-- Stream object to capture the changes.
create or replace stream stage_sch.customer_stm
on table stage_sch.customer
append_only = true
comment = 'This is the append-only stream object on customer table that only gets delta data';
-- run copy command to load the data into stage-customer table.
copy into stage_sch.customer (customerid, name, mobile, email, loginbyusing, gender, dob, anniversary,
preferences, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as customerid,
t.$2::text as name,
t.$3::text as mobile,
t.$4::text as email,
t.$5::text as loginbyusing,
t.$6::text as gender,
t.$7::text as dob,
t.$8::text as anniversary,
t.$9::text as preferences,
t.$10::text as createddate,
t.$11::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/initial/customer/customers-initial.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
select * from stage_sch.customer limit 10;
select count(*) from stage_sch.customer; -- 99899
select count(*) from stage_sch.customer_stm;
-- Part-2 Clean Layer
--
CREATE OR REPLACE TABLE CLEAN_SCH.CUSTOMER (
CUSTOMER_SK NUMBER AUTOINCREMENT PRIMARY KEY, -- Auto-incremented primary key
CUSTOMER_ID STRING NOT NULL, -- Customer ID
NAME STRING(100) NOT NULL, -- Customer name
MOBILE STRING(15) WITH TAG (common.pii_policy_tag = 'PII'), -- Mobile number, accommodating international format
EMAIL STRING(100) WITH TAG (common.pii_policy_tag = 'EMAIL'), -- Email
LOGIN_BY_USING STRING(50), -- Method of login (e.g., Social, Google, etc.)
GENDER STRING(10) WITH TAG (common.pii_policy_tag = 'PII'), -- Gender
DOB DATE WITH TAG (common.pii_policy_tag = 'PII'), -- Date of birth in DATE format
ANNIVERSARY DATE, -- Anniversary in DATE format
PREFERENCES STRING, -- Customer preferences
CREATED_DT TIMESTAMP_TZ DEFAULT CURRENT_TIMESTAMP, -- Record creation timestamp
MODIFIED_DT TIMESTAMP_TZ, -- Record modification timestamp, allows NULL if not modified
-- Additional audit columns
_STG_FILE_NAME STRING, -- File name for audit
_STG_FILE_LOAD_TS TIMESTAMP_NTZ, -- File load timestamp
_STG_FILE_MD5 STRING, -- MD5 hash for file content
_COPY_DATA_TS TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP -- Copy data timestamp
)
comment = 'Customer entity under clean schema with appropriate data type under clean schema layer, data is populated using merge statement from the stage layer location table. This table does not support SCD2';
-- Stream object to capture the changes.
create or replace stream CLEAN_SCH.customer_stm
on table CLEAN_SCH.customer
comment = 'This is the stream object on customer entity to track insert, update, and delete changes';
insert into clean_sch.customer (
customer_id,
name,
mobile,
email,
login_by_using,
gender,
dob,
anniversary,
preferences,
created_dt,
modified_dt,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
_copy_data_ts
)
select
customerid::string,
name::string,
mobile::string,
email::string,
loginbyusing::string,
gender::string,
try_to_date(dob, 'YYYY-MM-DD') as dob, -- converting dob to date
try_to_date(anniversary, 'YYYY-MM-DD') as anniversary, -- converting anniversary to date
preferences::string,
try_to_timestamp_tz(createddate, 'YYYY-MM-DD HH24:MI:SS') as created_dt, -- timestamp conversion
try_to_timestamp_tz(modifieddate, 'YYYY-MM-DD HH24:MI:SS') as modified_dt, -- timestamp conversion
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
_copy_data_ts
from stage_sch.customer;
MERGE INTO CLEAN_SCH.CUSTOMER AS target
USING (
SELECT
CUSTOMERID::STRING AS CUSTOMER_ID,
NAME::STRING AS NAME,
MOBILE::STRING AS MOBILE,
EMAIL::STRING AS EMAIL,
LOGINBYUSING::STRING AS LOGIN_BY_USING,
GENDER::STRING AS GENDER,
TRY_TO_DATE(DOB, 'YYYY-MM-DD') AS DOB,
TRY_TO_DATE(ANNIVERSARY, 'YYYY-MM-DD') AS ANNIVERSARY,
PREFERENCES::STRING AS PREFERENCES,
TRY_TO_TIMESTAMP_TZ(CREATEDDATE, 'YYYY-MM-DD"T"HH24:MI:SS.FF6') AS CREATED_DT,
TRY_TO_TIMESTAMP_TZ(MODIFIEDDATE, 'YYYY-MM-DD"T"HH24:MI:SS.FF6') AS MODIFIED_DT,
_STG_FILE_NAME,
_STG_FILE_LOAD_TS,
_STG_FILE_MD5,
_COPY_DATA_TS
FROM STAGE_SCH.CUSTOMER_STM
) AS source
ON target.CUSTOMER_ID = source.CUSTOMER_ID
WHEN MATCHED THEN
UPDATE SET
target.NAME = source.NAME,
target.MOBILE = source.MOBILE,
target.EMAIL = source.EMAIL,
target.LOGIN_BY_USING = source.LOGIN_BY_USING,
target.GENDER = source.GENDER,
target.DOB = source.DOB,
target.ANNIVERSARY = source.ANNIVERSARY,
target.PREFERENCES = source.PREFERENCES,
target.CREATED_DT = source.CREATED_DT,
target.MODIFIED_DT = source.MODIFIED_DT,
target._STG_FILE_NAME = source._STG_FILE_NAME,
target._STG_FILE_LOAD_TS = source._STG_FILE_LOAD_TS,
target._STG_FILE_MD5 = source._STG_FILE_MD5,
target._COPY_DATA_TS = source._COPY_DATA_TS
WHEN NOT MATCHED THEN
INSERT (
CUSTOMER_ID,
NAME,
MOBILE,
EMAIL,
LOGIN_BY_USING,
GENDER,
DOB,
ANNIVERSARY,
PREFERENCES,
CREATED_DT,
MODIFIED_DT,
_STG_FILE_NAME,
_STG_FILE_LOAD_TS,
_STG_FILE_MD5,
_COPY_DATA_TS
)
VALUES (
source.CUSTOMER_ID,
source.NAME,
source.MOBILE,
source.EMAIL,
source.LOGIN_BY_USING,
source.GENDER,
source.DOB,
source.ANNIVERSARY,
source.PREFERENCES,
source.CREATED_DT,
source.MODIFIED_DT,
source._STG_FILE_NAME,
source._STG_FILE_LOAD_TS,
source._STG_FILE_MD5,
source._COPY_DATA_TS
);
-- create dim table
CREATE OR REPLACE TABLE CONSUMPTION_SCH.CUSTOMER_DIM (
CUSTOMER_HK NUMBER PRIMARY KEY, -- Surrogate key for the customer
CUSTOMER_ID STRING NOT NULL, -- Natural key for the customer
NAME STRING(100) NOT NULL, -- Customer name
MOBILE STRING(15) WITH TAG (common.pii_policy_tag = 'PII'), -- Mobile number
EMAIL STRING(100) WITH TAG (common.pii_policy_tag = 'EMAIL'), -- Email
LOGIN_BY_USING STRING(50), -- Method of login
GENDER STRING(10) WITH TAG (common.pii_policy_tag = 'PII'), -- Gender
DOB DATE WITH TAG (common.pii_policy_tag = 'PII'), -- Date of birth
ANNIVERSARY DATE, -- Anniversary
PREFERENCES STRING, -- Preferences
EFF_START_DATE TIMESTAMP_TZ, -- Effective start date
EFF_END_DATE TIMESTAMP_TZ, -- Effective end date (NULL if active)
IS_CURRENT BOOLEAN -- Flag to indicate the current record
)
COMMENT = 'Customer Dimension table with SCD Type 2 handling for historical tracking.';
MERGE INTO
CONSUMPTION_SCH.CUSTOMER_DIM AS target
USING
CLEAN_SCH.CUSTOMER_STM AS source
ON
target.CUSTOMER_ID = source.CUSTOMER_ID AND
target.NAME = source.NAME AND
target.MOBILE = source.MOBILE AND
target.EMAIL = source.EMAIL AND
target.LOGIN_BY_USING = source.LOGIN_BY_USING AND
target.GENDER = source.GENDER AND
target.DOB = source.DOB AND
target.ANNIVERSARY = source.ANNIVERSARY AND
target.PREFERENCES = source.PREFERENCES
WHEN MATCHED
AND source.METADATA$ACTION = 'DELETE' AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Update the existing record to close its validity period
UPDATE SET
target.EFF_END_DATE = CURRENT_TIMESTAMP(),
target.IS_CURRENT = FALSE
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT' AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Insert new record with current data and new effective start date
INSERT (
CUSTOMER_HK,
CUSTOMER_ID,
NAME,
MOBILE,
EMAIL,
LOGIN_BY_USING,
GENDER,
DOB,
ANNIVERSARY,
PREFERENCES,
EFF_START_DATE,
EFF_END_DATE,
IS_CURRENT
)
VALUES (
hash(SHA1_hex(CONCAT(source.CUSTOMER_ID, source.NAME, source.MOBILE,
source.EMAIL, source.LOGIN_BY_USING, source.GENDER, source.DOB,
source.ANNIVERSARY, source.PREFERENCES))),
source.CUSTOMER_ID,
source.NAME,
source.MOBILE,
source.EMAIL,
source.LOGIN_BY_USING,
source.GENDER,
source.DOB,
source.ANNIVERSARY,
source.PREFERENCES,
CURRENT_TIMESTAMP(),
NULL,
TRUE
)
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT' AND source.METADATA$ISUPDATE = 'FALSE' THEN
-- Insert new record with current data and new effective start date
INSERT (
CUSTOMER_HK,
CUSTOMER_ID,
NAME,
MOBILE,
EMAIL,
LOGIN_BY_USING,
GENDER,
DOB,
ANNIVERSARY,
PREFERENCES,
EFF_START_DATE,
EFF_END_DATE,
IS_CURRENT
)
VALUES (
hash(SHA1_hex(CONCAT(source.CUSTOMER_ID, source.NAME, source.MOBILE,
source.EMAIL, source.LOGIN_BY_USING, source.GENDER, source.DOB,
source.ANNIVERSARY, source.PREFERENCES))),
source.CUSTOMER_ID,
source.NAME,
source.MOBILE,
source.EMAIL,
source.LOGIN_BY_USING,
source.GENDER,
source.DOB,
source.ANNIVERSARY,
source.PREFERENCES,
CURRENT_TIMESTAMP(),
NULL,
TRUE
);
// ----------------------------------------------------------
// ----------------------------------------------------------
-- delta processing check
list @stage_sch.csv_stg/delta/customer/;
copy into stage_sch.customer (customerid, name, mobile, email, loginbyusing, gender, dob, anniversary,
preferences, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as customerid,
t.$2::text as name,
t.$3::text as mobile,
t.$4::text as email,
t.$5::text as loginbyusing,
t.$6::text as gender,
t.$7::text as dob,
t.$8::text as anniversary,
t.$9::text as preferences,
t.$10::text as createddate,
t.$11::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/delta/customer/day-01-insert-customer.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
-- ------------------------------------------------
-- Part -2 loading the delta data
list @stage_sch.csv_stg/delta/customer/;
copy into stage_sch.customer (customerid, name, mobile, email, loginbyusing, gender, dob, anniversary,
preferences, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as customerid,
t.$2::text as name,
t.$3::text as mobile,
t.$4::text as email,
t.$5::text as loginbyusing,
t.$6::text as gender,
t.$7::text as dob,
t.$8::text as anniversary,
t.$9::text as preferences,
t.$10::text as createddate,
t.$11::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/delta/customer/day-02-insert-update.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;Customer Address Dimension — SQL Scripts

use role sysadmin;
use database sandbox;
use schema stage_sch;
use warehouse adhoc_wh;
create or replace table stage_sch.customeraddress (
addressid text, -- primary key as text
customerid text comment 'Customer FK (Source Data)', -- foreign key reference as text (no constraint in snowflake)
flatno text, -- flat number as text
houseno text, -- house number as text
floor text, -- floor as text
building text, -- building name as text
landmark text, -- landmark as text
locality text, -- locality as text
city text, -- city as text
state text, -- state as text
pincode text, -- pincode as text
coordinates text, -- coordinates as text
primaryflag text, -- primary flag as text
addresstype text, -- address type as text
createddate text, -- created date as text
modifieddate text, -- modified date as text
-- audit columns with appropriate data types
_stg_file_name text,
_stg_file_load_ts timestamp,
_stg_file_md5 text,
_copy_data_ts timestamp default current_timestamp
)
comment = 'This is the customer address stage/raw table where data will be copied from internal stage using copy command. This is as-is data represetation from the source location. All the columns are text data type except the audit columns that are added for traceability.';
create or replace stream stage_sch.customeraddress_stm
on table stage_sch.customeraddress
append_only = true
comment = 'This is the append-only stream object on customer address table that only gets delta data';
select * from stage_sch.customeraddress_stm;
copy into stage_sch.customeraddress (addressid, customerid, flatno, houseno, floor, building,
landmark, locality,city,pincode, state, coordinates, primaryflag, addresstype,
createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as addressid,
t.$2::text as customerid,
t.$3::text as flatno,
t.$4::text as houseno,
t.$5::text as floor,
t.$6::text as building,
t.$7::text as landmark,
t.$8::text as locality,
t.$9::text as city,
t.$10::text as State,
t.$11::text as Pincode,
t.$12::text as coordinates,
t.$13::text as primaryflag,
t.$14::text as addresstype,
t.$15::text as createddate,
t.$16::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/initial/customer-address t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
-- 2nd layer
CREATE OR REPLACE TABLE CLEAN_SCH.CUSTOMER_ADDRESS (
CUSTOMER_ADDRESS_SK NUMBER AUTOINCREMENT PRIMARY KEY comment 'Surrogate Key (EWH)', -- Auto-incremented primary key
ADDRESS_ID INT comment 'Primary Key (Source Data)', -- Primary key as string
CUSTOMER_ID_FK INT comment 'Customer FK (Source Data)', -- Foreign key reference as string (no constraint in Snowflake)
FLAT_NO STRING, -- Flat number as string
HOUSE_NO STRING, -- House number as string
FLOOR STRING, -- Floor as string
BUILDING STRING, -- Building name as string
LANDMARK STRING, -- Landmark as string
locality STRING, -- locality as string
CITY STRING, -- City as string
STATE STRING, -- State as string
PINCODE STRING, -- Pincode as string
COORDINATES STRING, -- Coordinates as string
PRIMARY_FLAG STRING, -- Primary flag as string
ADDRESS_TYPE STRING, -- Address type as string
CREATED_DATE TIMESTAMP_TZ, -- Created date as timestamp with time zone
MODIFIED_DATE TIMESTAMP_TZ, -- Modified date as timestamp with time zone
-- Audit columns with appropriate data types
_STG_FILE_NAME STRING,
_STG_FILE_LOAD_TS TIMESTAMP,
_STG_FILE_MD5 STRING,
_COPY_DATA_TS TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
comment = 'Customer address entity under clean schema with appropriate data type under clean schema layer, data is populated using merge statement from the stage layer location table. This table does not support SCD2';
-- Stream object to capture the changes.
create or replace stream CLEAN_SCH.CUSTOMER_ADDRESS_STM
on table CLEAN_SCH.CUSTOMER_ADDRESS
comment = 'This is the stream object on customer address entity to track insert, update, and delete changes';
MERGE INTO clean_sch.customer_address AS clean
USING (
SELECT
CAST(addressid AS INT) AS address_id,
CAST(customerid AS INT) AS customer_id_fk,
flatno AS flat_no,
houseno AS house_no,
floor,
building,
landmark,
locality,
city,
state,
pincode,
coordinates,
primaryflag AS primary_flag,
addresstype AS address_type,
TRY_TO_TIMESTAMP_TZ(createddate, 'YYYY-MM-DD"T"HH24:MI:SS') AS created_date,
TRY_TO_TIMESTAMP_TZ(modifieddate, 'YYYY-MM-DD"T"HH24:MI:SS') AS modified_date,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
_copy_data_ts
FROM stage_sch.customeraddress_stm
) AS stage
ON clean.address_id = stage.address_id
-- Insert new records
WHEN NOT MATCHED THEN
INSERT (
address_id,
customer_id_fk,
flat_no,
house_no,
floor,
building,
landmark,
locality,
city,
state,
pincode,
coordinates,
primary_flag,
address_type,
created_date,
modified_date,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
_copy_data_ts
)
VALUES (
stage.address_id,
stage.customer_id_fk,
stage.flat_no,
stage.house_no,
stage.floor,
stage.building,
stage.landmark,
stage.locality,
stage.city,
stage.state,
stage.pincode,
stage.coordinates,
stage.primary_flag,
stage.address_type,
stage.created_date,
stage.modified_date,
stage._stg_file_name,
stage._stg_file_load_ts,
stage._stg_file_md5,
stage._copy_data_ts
)
-- Update existing records
WHEN MATCHED THEN
UPDATE SET
clean.flat_no = stage.flat_no,
clean.house_no = stage.house_no,
clean.floor = stage.floor,
clean.building = stage.building,
clean.landmark = stage.landmark,
clean.locality = stage.locality,
clean.city = stage.city,
clean.state = stage.state,
clean.pincode = stage.pincode,
clean.coordinates = stage.coordinates,
clean.primary_flag = stage.primary_flag,
clean.address_type = stage.address_type,
clean.created_date = stage.created_date,
clean.modified_date = stage.modified_date,
clean._stg_file_name = stage._stg_file_name,
clean._stg_file_load_ts = stage._stg_file_load_ts,
clean._stg_file_md5 = stage._stg_file_md5,
clean._copy_data_ts = stage._copy_data_ts;
CREATE OR REPLACE TABLE CONSUMPTION_SCH.CUSTOMER_ADDRESS_DIM (
CUSTOMER_ADDRESS_HK NUMBER PRIMARY KEY comment 'Customer Address HK (EDW)', -- Surrogate key (hash key)
ADDRESS_ID INT comment 'Primary Key (Source System)', -- Original primary key
CUSTOMER_ID_FK STRING comment 'Customer FK (Source System)', -- Surrogate key from Customer Dimension (Foreign Key)
FLAT_NO STRING, -- Flat number
HOUSE_NO STRING, -- House number
FLOOR STRING, -- Floor
BUILDING STRING, -- Building name
LANDMARK STRING, -- Landmark
LOCALITY STRING, -- Locality
CITY STRING, -- City
STATE STRING, -- State
PINCODE STRING, -- Pincode
COORDINATES STRING, -- Geo-coordinates
PRIMARY_FLAG STRING, -- Whether it's the primary address
ADDRESS_TYPE STRING, -- Type of address (e.g., Home, Office)
-- SCD2 Columns
EFF_START_DATE TIMESTAMP_TZ, -- Effective start date
EFF_END_DATE TIMESTAMP_TZ, -- Effective end date (NULL if active)
IS_CURRENT BOOLEAN -- Flag to indicate the current record
);
-- select * from CLEAN_SCH.CUSTOMER_ADDRESS_STM;
MERGE INTO
CONSUMPTION_SCH.CUSTOMER_ADDRESS_DIM AS target
USING
CLEAN_SCH.CUSTOMER_ADDRESS_STM AS source
ON
target.ADDRESS_ID = source.ADDRESS_ID AND
target.CUSTOMER_ID_FK = source.CUSTOMER_ID_FK AND
target.FLAT_NO = source.FLAT_NO AND
target.HOUSE_NO = source.HOUSE_NO AND
target.FLOOR = source.FLOOR AND
target.BUILDING = source.BUILDING AND
target.LANDMARK = source.LANDMARK AND
target.LOCALITY = source.LOCALITY AND
target.CITY = source.CITY AND
target.STATE = source.STATE AND
target.PINCODE = source.PINCODE AND
target.COORDINATES = source.COORDINATES AND
target.PRIMARY_FLAG = source.PRIMARY_FLAG AND
target.ADDRESS_TYPE = source.ADDRESS_TYPE
WHEN MATCHED
AND source.METADATA$ACTION = 'DELETE' AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Update the existing record to close its validity period
UPDATE SET
target.EFF_END_DATE = CURRENT_TIMESTAMP(),
target.IS_CURRENT = FALSE
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT' AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Insert new record with current data and new effective start date
INSERT (
CUSTOMER_ADDRESS_HK,
ADDRESS_ID,
CUSTOMER_ID_FK,
FLAT_NO,
HOUSE_NO,
FLOOR,
BUILDING,
LANDMARK,
LOCALITY,
CITY,
STATE,
PINCODE,
COORDINATES,
PRIMARY_FLAG,
ADDRESS_TYPE,
EFF_START_DATE,
EFF_END_DATE,
IS_CURRENT
)
VALUES (
hash(SHA1_hex(CONCAT(source.ADDRESS_ID, source.CUSTOMER_ID_FK, source.FLAT_NO,
source.HOUSE_NO, source.FLOOR, source.BUILDING, source.LANDMARK,
source.LOCALITY, source.CITY, source.STATE, source.PINCODE,
source.COORDINATES, source.PRIMARY_FLAG, source.ADDRESS_TYPE))),
source.ADDRESS_ID,
source.CUSTOMER_ID_FK,
source.FLAT_NO,
source.HOUSE_NO,
source.FLOOR,
source.BUILDING,
source.LANDMARK,
source.LOCALITY,
source.CITY,
source.STATE,
source.PINCODE,
source.COORDINATES,
source.PRIMARY_FLAG,
source.ADDRESS_TYPE,
CURRENT_TIMESTAMP(),
NULL,
TRUE
)
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT' AND source.METADATA$ISUPDATE = 'FALSE' THEN
-- Insert new record with current data and new effective start date
INSERT (
CUSTOMER_ADDRESS_HK,
ADDRESS_ID,
CUSTOMER_ID_FK,
FLAT_NO,
HOUSE_NO,
FLOOR,
BUILDING,
LANDMARK,
LOCALITY,
CITY,
STATE,
PINCODE,
COORDINATES,
PRIMARY_FLAG,
ADDRESS_TYPE,
EFF_START_DATE,
EFF_END_DATE,
IS_CURRENT
)
VALUES (
hash(SHA1_hex(CONCAT(source.ADDRESS_ID, source.CUSTOMER_ID_FK, source.FLAT_NO,
source.HOUSE_NO, source.FLOOR, source.BUILDING, source.LANDMARK,
source.LOCALITY, source.CITY, source.STATE, source.PINCODE,
source.COORDINATES, source.PRIMARY_FLAG, source.ADDRESS_TYPE))),
source.ADDRESS_ID,
source.CUSTOMER_ID_FK,
source.FLAT_NO,
source.HOUSE_NO,
source.FLOOR,
source.BUILDING,
source.LANDMARK,
source.LOCALITY,
source.CITY,
source.STATE,
source.PINCODE,
source.COORDINATES,
source.PRIMARY_FLAG,
source.ADDRESS_TYPE,
CURRENT_TIMESTAMP(),
NULL,
TRUE
);
--
select * from stage_sch.customeraddressbook;
select * from CLEAN_SCH.CUSTOMER_ADDRESS_BOOK;
select * from CONSUMPTION_SCH.CUSTOMER_ADDRESS_BOOK_DIM;
list @stage_sch.csv_stg/delta/customer-address;
copy into stage_sch.customeraddress (addressid, customerid, flatno, houseno, floor, building,
landmark, locality,city,pincode, state, coordinates, primaryflag, addresstype,
createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as addressid,
t.$2::text as customerid,
t.$3::text as flatno,
t.$4::text as houseno,
t.$5::text as floor,
t.$6::text as building,
t.$7::text as landmark,
t.$8::text as locality,
t.$9::text as city,
t.$10::text as State,
t.$11::text as Pincode,
t.$12::text as coordinates,
t.$13::text as primaryflag,
t.$14::text as addresstype,
t.$15::text as createddate,
t.$16::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/delta/customer-address/ t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;Menu Dimension — SQL Script

use role sysadmin;
use database sandbox;
use schema stage_sch;
use warehouse adhoc_wh;
create or replace table stage_sch.menu (
menuid text comment 'Primary Key (Source System)', -- primary key as text
restaurantid text comment 'Restaurant FK(Source System)', -- foreign key reference as text (no constraint in snowflake)
itemname text, -- item name as text
description text, -- description as text
price text, -- price as text (no decimal constraint)
category text, -- category as text
availability text, -- availability as text
itemtype text, -- item type as text
createddate text, -- created date as text
modifieddate text, -- modified date as text
-- audit columns with appropriate data types
_stg_file_name text,
_stg_file_load_ts timestamp,
_stg_file_md5 text,
_copy_data_ts timestamp default current_timestamp
)
comment = 'This is the menu stage/raw table where data will be copied from internal stage using copy command. This is as-is data represetation from the source location. All the columns are text data type except the audit columns that are added for traceability.';
-- Stream object to capture the changes.
create or replace stream stage_sch.menu_stm
on table stage_sch.menu
append_only = true
comment = 'This is the append-only stream object on menu entity that only gets delta data';
list @stage_sch.csv_stg/initial/menu;
copy into stage_sch.menu (menuid, restaurantid, itemname, description, price, category,
availability, itemtype, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as menuid,
t.$2::text as restaurantid,
t.$3::text as itemname,
t.$4::text as description,
t.$5::text as price,
t.$6::text as category,
t.$7::text as availability,
t.$8::text as itemtype,
t.$9::text as createddate,
t.$10::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/initial/menu t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
select * from menu limit 10;
select *
from table(information_schema.copy_history(table_name=>'MENU', start_time=> dateadd(hours, -1, current_timestamp())));
CREATE OR REPLACE TABLE clean_sch.menu (
Menu_SK INT AUTOINCREMENT PRIMARY KEY comment 'Surrogate Key (EDW)', -- Auto-incrementing primary key for internal tracking
Menu_ID INT NOT NULL UNIQUE comment 'Primary Key (Source System)' , -- Unique and non-null Menu_ID
Restaurant_ID_FK INT comment 'Restaurant FK(Source System)' , -- Identifier for the restaurant
Item_Name STRING not null, -- Name of the menu item
Description STRING not null, -- Description of the menu item
Price DECIMAL(10, 2) not null, -- Price as a numeric value with 2 decimal places
Category STRING, -- Food category (e.g., North Indian)
Availability BOOLEAN, -- Availability status (True/False)
Item_Type STRING, -- Dietary classification (e.g., Vegan)
Created_dt TIMESTAMP_NTZ, -- Date when the record was created
Modified_dt TIMESTAMP_NTZ, -- Date when the record was last modified
-- Audit columns for traceability
_STG_FILE_NAME STRING, -- Source file name
_STG_FILE_LOAD_TS TIMESTAMP_NTZ, -- Timestamp when data was loaded from the staging layer
_STG_FILE_MD5 STRING, -- MD5 hash of the source file
_COPY_DATA_TS TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP -- Timestamp when data was copied to the clean layer
)
comment = 'Menu entity under clean schema with appropriate data type under clean schema layer, data is populated using merge statement from the stage layer location table. This table does not support SCD2';
create or replace stream CLEAN_SCH.menu_stm
on table CLEAN_SCH.menu
comment = 'This is the stream object on menu table table to track insert, update, and delete changes';
MERGE INTO clean_sch.menu AS target
USING (
SELECT
TRY_CAST(menuid AS INT) AS Menu_ID,
TRY_CAST(restaurantid AS INT) AS Restaurant_ID_FK,
TRIM(itemname) AS Item_Name,
TRIM(description) AS Description,
TRY_CAST(price AS DECIMAL(10, 2)) AS Price,
TRIM(category) AS Category,
CASE
WHEN LOWER(availability) = 'true' THEN TRUE
WHEN LOWER(availability) = 'false' THEN FALSE
ELSE NULL
END AS Availability,
TRIM(itemtype) AS Item_Type,
TRY_CAST(createddate AS TIMESTAMP_NTZ) AS Created_dt, -- Renamed column
TRY_CAST(modifieddate AS TIMESTAMP_NTZ) AS Modified_dt, -- Renamed column
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
_copy_data_ts
FROM stage_sch.menu
) AS source
ON target.Menu_ID = source.Menu_ID
WHEN MATCHED THEN
UPDATE SET
Restaurant_ID_FK = source.Restaurant_ID_FK,
Item_Name = source.Item_Name,
Description = source.Description,
Price = source.Price,
Category = source.Category,
Availability = source.Availability,
Item_Type = source.Item_Type,
Created_dt = source.Created_dt,
Modified_dt = source.Modified_dt,
_STG_FILE_NAME = source._stg_file_name,
_STG_FILE_LOAD_TS = source._stg_file_load_ts,
_STG_FILE_MD5 = source._stg_file_md5,
_COPY_DATA_TS = CURRENT_TIMESTAMP
WHEN NOT MATCHED THEN
INSERT (
Menu_ID,
Restaurant_ID_FK,
Item_Name,
Description,
Price,
Category,
Availability,
Item_Type,
Created_dt,
Modified_dt,
_STG_FILE_NAME,
_STG_FILE_LOAD_TS,
_STG_FILE_MD5,
_COPY_DATA_TS
)
VALUES (
source.Menu_ID,
source.Restaurant_ID_FK,
source.Item_Name,
source.Description,
source.Price,
source.Category,
source.Availability,
source.Item_Type,
source.Created_dt,
source.Modified_dt,
source._stg_file_name,
source._stg_file_load_ts,
source._stg_file_md5,
CURRENT_TIMESTAMP
);
CREATE OR REPLACE TABLE consumption_sch.menu_dim (
Menu_Dim_HK NUMBER primary key comment 'Menu Dim HK (EDW)', -- Hash key generated for Menu Dim table
Menu_ID INT NOT NULL comment 'Primary Key (Source System)', -- Unique and non-null Menu_ID
Restaurant_ID_FK INT NOT NULL comment 'Restaurant FK (Source System)', -- Identifier for the restaurant
Item_Name STRING, -- Name of the menu item
Description STRING, -- Description of the menu item
Price DECIMAL(10, 2), -- Price as a numeric value with 2 decimal places
Category STRING, -- Food category (e.g., North Indian)
Availability BOOLEAN, -- Availability status (True/False)
Item_Type STRING, -- Dietary classification (e.g., Vegan)
EFF_START_DATE TIMESTAMP_NTZ, -- Effective start date of the record
EFF_END_DATE TIMESTAMP_NTZ, -- Effective end date of the record
IS_CURRENT BOOLEAN -- Flag to indicate if the record is current (True/False)
)
COMMENT = 'This table stores the dimension data for the menu items, tracking historical changes using SCD Type 2. Each menu item has an effective start and end date, with a flag indicating if it is the current record or historical. The hash key (Menu_Dim_HK) is generated based on Menu_ID and Restaurant_ID.';
MERGE INTO
consumption_sch.MENU_DIM AS target
USING
CLEAN_SCH.MENU_STM AS source
ON
target.Menu_ID = source.Menu_ID AND
target.Restaurant_ID_FK = source.Restaurant_ID_FK AND
target.Item_Name = source.Item_Name AND
target.Description = source.Description AND
target.Price = source.Price AND
target.Category = source.Category AND
target.Availability = source.Availability AND
target.Item_Type = source.Item_Type
WHEN MATCHED
AND source.METADATA$ACTION = 'DELETE'
AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Update the existing record to close its validity period
UPDATE SET
target.EFF_END_DATE = CURRENT_TIMESTAMP(),
target.IS_CURRENT = FALSE
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT'
AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Insert new record with current data and new effective start date
INSERT (
Menu_Dim_HK, -- Hash key
Menu_ID,
Restaurant_ID_FK,
Item_Name,
Description,
Price,
Category,
Availability,
Item_Type,
EFF_START_DATE,
EFF_END_DATE,
IS_CURRENT
)
VALUES (
hash(SHA1_hex(CONCAT(source.Menu_ID, source.Restaurant_ID_FK,
source.Item_Name, source.Description, source.Price,
source.Category, source.Availability, source.Item_Type))), -- Hash key
source.Menu_ID,
source.Restaurant_ID_FK,
source.Item_Name,
source.Description,
source.Price,
source.Category,
source.Availability,
source.Item_Type,
CURRENT_TIMESTAMP(), -- Effective start date
NULL, -- Effective end date (NULL for current record)
TRUE -- IS_CURRENT = TRUE for new record
)
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT'
AND source.METADATA$ISUPDATE = 'FALSE' THEN
-- Insert new record with current data and new effective start date
INSERT (
Menu_Dim_HK, -- Hash key
Menu_ID,
Restaurant_ID_FK,
Item_Name,
Description,
Price,
Category,
Availability,
Item_Type,
EFF_START_DATE,
EFF_END_DATE,
IS_CURRENT
)
VALUES (
hash(SHA1_hex(CONCAT(source.Menu_ID, source.Restaurant_ID_FK,
source.Item_Name, source.Description, source.Price,
source.Category, source.Availability, source.Item_Type))), -- Hash key
source.Menu_ID,
source.Restaurant_ID_FK,
source.Item_Name,
source.Description,
source.Price,
source.Category,
source.Availability,
source.Item_Type,
CURRENT_TIMESTAMP(), -- Effective start date
NULL, -- Effective end date (NULL for current record)
TRUE -- IS_CURRENT = TRUE for new record
);
-- Part -2
list @stage_sch.csv_stg/delta/menu;
copy into stage_sch.menu (menuid, restaurantid, itemname, description, price, category,
availability, itemtype, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as menuid,
t.$2::text as restaurantid,
t.$3::text as itemname,
t.$4::text as description,
t.$5::text as price,
t.$6::text as category,
t.$7::text as availability,
t.$8::text as itemtype,
t.$9::text as createddate,
t.$10::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/delta/menu/ t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;Delivery Agent Dimension — SQL Script

use role sysadmin;
use database sandbox;
use schema stage_sch;
use warehouse adhoc_wh;
create or replace table stage_sch.deliveryagent (
deliveryagentid text comment 'Primary Key (Source System)', -- primary key as text
name text, -- name as text, required field
phone text, -- phone as text, unique constraint indicated
vehicletype text, -- vehicle type as text
locationid text, -- foreign key reference as text (no constraint in snowflake)
status text, -- status as text
gender text, -- status as text
rating text, -- rating as text
createddate text, -- created date as text
modifieddate text, -- modified date as text
-- audit columns with appropriate data types
_stg_file_name text,
_stg_file_load_ts timestamp,
_stg_file_md5 text,
_copy_data_ts timestamp default current_timestamp
)
comment = 'This is the delivery stage/raw table where data will be copied from internal stage using copy command. This is as-is data represetation from the source location. All the columns are text data type except the audit columns that are added for traceability.';
create or replace stream stage_sch.deliveryagent_stm
on table stage_sch.deliveryagent
append_only = true
comment = 'This is the append-only stream object on delivery agent table that only gets delta data';
copy into stage_sch.deliveryagent (deliveryagentid, name, phone, vehicletype, locationid,
status, gender, rating, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as deliveryagentid,
t.$2::text as name,
t.$3::text as phone,
t.$4::text as vehicletype,
t.$5::text as locationid,
t.$6::text as status,
t.$7::text as gender,
t.$8::text as rating,
t.$9::text as createddate,
t.$10::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/initial/delivery-agent t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
select count(*) from stage_sch.deliveryagent;
select * from stage_sch.deliveryagent_stm;
CREATE OR REPLACE TABLE clean_sch.delivery_agent (
delivery_agent_sk INT AUTOINCREMENT PRIMARY KEY comment 'Surrogate Key (EDW)', -- Primary key with auto-increment
delivery_agent_id INT NOT NULL UNIQUE comment 'Primary Key (Source System)', -- Delivery agent ID as integer
name STRING NOT NULL, -- Name as string, required field
phone STRING NOT NULL, -- Phone as string, unique constraint
vehicle_type STRING NOT NULL, -- Vehicle type as string
location_id_fk INT comment 'Location FK(Source System)', -- Location ID as integer
status STRING, -- Status as string
gender STRING, -- Gender as string
rating number(4,2), -- Rating as float
created_dt TIMESTAMP_NTZ, -- Created date as timestamp without timezone
modified_dt TIMESTAMP_NTZ, -- Modified date as timestamp without timezone
-- Audit columns with appropriate data types
_stg_file_name STRING, -- Staging file name as string
_stg_file_load_ts TIMESTAMP, -- Staging file load timestamp
_stg_file_md5 STRING, -- Staging file MD5 hash as string
_copy_data_ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- Data copy timestamp with default value
)
comment = 'Delivery entity under clean schema with appropriate data type under clean schema layer, data is populated using merge statement from the stage layer location table. This table does not support SCD2';
create or replace stream CLEAN_SCH.delivery_agent_stm
on table CLEAN_SCH.delivery_agent
comment = 'This is the stream object on delivery agent table table to track insert, update, and delete changes';
MERGE INTO clean_sch.delivery_agent AS target
USING stage_sch.deliveryagent_stm AS source
ON target.delivery_agent_id = source.deliveryagentid
WHEN MATCHED THEN
UPDATE SET
target.phone = source.phone,
target.vehicle_type = source.vehicletype,
target.location_id_fk = TRY_TO_NUMBER(source.locationid),
target.status = source.status,
target.gender = source.gender,
target.rating = TRY_TO_DECIMAL(source.rating,4,2),
target.created_dt = TRY_TO_TIMESTAMP(source.createddate),
target.modified_dt = TRY_TO_TIMESTAMP(source.modifieddate),
target._stg_file_name = source._stg_file_name,
target._stg_file_load_ts = source._stg_file_load_ts,
target._stg_file_md5 = source._stg_file_md5,
target._copy_data_ts = source._copy_data_ts
WHEN NOT MATCHED THEN
INSERT (
delivery_agent_id,
name,
phone,
vehicle_type,
location_id_fk,
status,
gender,
rating,
created_dt,
modified_dt,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
_copy_data_ts
)
VALUES (
TRY_TO_NUMBER(source.deliveryagentid),
source.name,
source.phone,
source.vehicletype,
TRY_TO_NUMBER(source.locationid),
source.status,
source.gender,
TRY_TO_NUMBER(source.rating),
TRY_TO_TIMESTAMP(source.createddate),
TRY_TO_TIMESTAMP(source.modifieddate),
source._stg_file_name,
source._stg_file_load_ts,
source._stg_file_md5,
CURRENT_TIMESTAMP()
);
select * from CLEAN_SCH.delivery_agent_stm ;
CREATE OR REPLACE TABLE consumption_sch.delivery_agent_dim (
delivery_agent_hk number primary key comment 'Delivery Agend Dim HK (EDW)', -- Hash key for unique identification
delivery_agent_id NUMBER not null comment 'Primary Key (Source System)', -- Business key
name STRING NOT NULL, -- Delivery agent name
phone STRING UNIQUE, -- Phone number, unique
vehicle_type STRING, -- Type of vehicle
location_id_fk NUMBER NOT NULL comment 'Location FK (Source System)', -- Location ID
status STRING, -- Current status of the delivery agent
gender STRING, -- Gender
rating NUMBER(4,2), -- Rating with one decimal precision
eff_start_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- Effective start date
eff_end_date TIMESTAMP, -- Effective end date (NULL for active record)
is_current BOOLEAN DEFAULT TRUE
)
comment = 'Dim table for delivery agent entity with SCD2 support.';
MERGE INTO consumption_sch.delivery_agent_dim AS target
USING CLEAN_SCH.delivery_agent_stm AS source
ON
target.delivery_agent_id = source.delivery_agent_id AND
target.name = source.name AND
target.phone = source.phone AND
target.vehicle_type = source.vehicle_type AND
target.location_id_fk = source.location_id_fk AND
target.status = source.status AND
target.gender = source.gender AND
target.rating = source.rating
WHEN MATCHED
AND source.METADATA$ACTION = 'DELETE'
AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Update the existing record to close its validity period
UPDATE SET
target.eff_end_date = CURRENT_TIMESTAMP,
target.is_current = FALSE
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT'
AND source.METADATA$ISUPDATE = 'TRUE' THEN
-- Insert new record with current data and new effective start date
INSERT (
delivery_agent_hk, -- Hash key
delivery_agent_id,
name,
phone,
vehicle_type,
location_id_fk,
status,
gender,
rating,
eff_start_date,
eff_end_date,
is_current
)
VALUES (
hash(SHA1_HEX(CONCAT(source.delivery_agent_id, source.name, source.phone,
source.vehicle_type, source.location_id_fk, source.status,
source.gender, source.rating))), -- Hash key
delivery_agent_id,
source.name,
source.phone,
source.vehicle_type,
location_id_fk,
source.status,
source.gender,
source.rating,
CURRENT_TIMESTAMP, -- Effective start date
NULL, -- Effective end date (NULL for current record)
TRUE -- IS_CURRENT = TRUE for new record
)
WHEN NOT MATCHED
AND source.METADATA$ACTION = 'INSERT'
AND source.METADATA$ISUPDATE = 'FALSE' THEN
-- Insert new record with current data and new effective start date
INSERT (
delivery_agent_hk, -- Hash key
delivery_agent_id,
name,
phone,
vehicle_type,
location_id_fk,
status,
gender,
rating,
eff_start_date,
eff_end_date,
is_current
)
VALUES (
hash(SHA1_HEX(CONCAT(source.delivery_agent_id, source.name, source.phone,
source.vehicle_type, source.location_id_fk, source.status,
source.gender, source.rating))), -- Hash key
source.delivery_agent_id,
source.name,
source.phone,
source.vehicle_type,
source.location_id_fk,
source.status,
source.gender,
source.rating,
CURRENT_TIMESTAMP, -- Effective start date
NULL, -- Effective end date (NULL for current record)
TRUE -- IS_CURRENT = TRUE for new record
);
-- part-2
copy into deliveryagent (deliveryagentid, name, phone, vehicletype, locationid,
status, gender, rating, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as deliveryagentid,
t.$2::text as name,
t.$3::text as phone,
t.$4::text as vehicletype,
t.$5::text as locationid,
t.$6::text as status,
t.$7::text as gender,
t.$8::text as rating,
t.$9::text as createddate,
t.$10::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/delta/delivery-agent/day-02-delivery-agent.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;Delivery Entity — SQL Scripts

use role sysadmin;
use database sandbox;
use schema stage_sch;
use warehouse adhoc_wh;
list @stage_sch.csv_stg/initial/delivery/;
-- this table may have additional information like picked time, accept time etc.
create or replace table stage_sch.delivery (
deliveryid text comment 'Primary Key (Source System)', -- foreign key reference as text (no constraint in snowflake)
orderid text comment 'Order FK (Source System)', -- foreign key reference as text (no constraint in snowflake)
deliveryagentid text comment 'Delivery Agent FK(Source System)', -- foreign key reference as text (no constraint in snowflake)
deliverystatus text, -- delivery status as text
estimatedtime text, -- estimated time as text
addressid text comment 'Customer Address FK(Source System)', -- foreign key reference as text (no constraint in snowflake)
deliverydate text, -- delivery date as text
createddate text, -- created date as text
modifieddate text, -- modified date as text
-- audit columns with appropriate data types
_stg_file_name text,
_stg_file_load_ts timestamp,
_stg_file_md5 text,
_copy_data_ts timestamp default current_timestamp
)
comment = 'This is the delivery stage/raw table where data will be copied from internal stage using copy command. This is as-is data represetation from the source location. All the columns are text data type except the audit columns that are added for traceability.';
create or replace stream stage_sch.delivery_stm
on table stage_sch.delivery
append_only = true
comment = 'this is the append-only stream object on delivery table that only gets delta data';
copy into stage_sch.delivery (deliveryid,orderid, deliveryagentid, deliverystatus,
estimatedtime, addressid, deliverydate, createddate,
modifieddate, _stg_file_name, _stg_file_load_ts,
_stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as deliveryid,
t.$2::text as orderid,
t.$3::text as deliveryagentid,
t.$4::text as deliverystatus,
t.$5::text as estimatedtime,
t.$6::text as addressid,
t.$7::text as deliverydate,
t.$8::text as createddate,
t.$9::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/initial/delivery/delivery-initial-load.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
CREATE OR REPLACE TABLE clean_sch.delivery (
delivery_sk INT AUTOINCREMENT PRIMARY KEY comment 'Surrogate Key (EDW)', -- Primary key with auto-increment
delivery_id INT NOT NULL comment 'Primary Key (Source System)',
order_id_fk NUMBER NOT NULL comment 'Order FK (Source System)', -- Foreign key reference, converted to numeric type
delivery_agent_id_fk NUMBER NOT NULL comment 'Delivery Agent FK (Source System)', -- Foreign key reference, converted to numeric type
delivery_status STRING, -- Delivery status, stored as a string
estimated_time STRING, -- Estimated time, stored as a string
customer_address_id_fk NUMBER NOT NULL comment 'Customer Address FK (Source System)', -- Foreign key reference, converted to numeric type
delivery_date TIMESTAMP, -- Delivery date, converted to timestamp
created_date TIMESTAMP, -- Created date, converted to timestamp
modified_date TIMESTAMP, -- Modified date, converted to timestamp
-- Audit columns with appropriate data types
_stg_file_name STRING, -- Source file name
_stg_file_load_ts TIMESTAMP, -- Source file load timestamp
_stg_file_md5 STRING, -- MD5 checksum of the source file
_copy_data_ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- Metadata timestamp
)
comment = 'Delivery entity under clean schema with appropriate data type under clean schema layer, data is populated using merge statement from the stage layer location table. This table does not support SCD2';
create or replace stream CLEAN_SCH.delivery_stm
on table CLEAN_SCH.delivery
comment = 'This is the stream object on delivery agent table table to track insert, update, and delete changes';
MERGE INTO
clean_sch.delivery AS target
USING
stage_sch.delivery_stm AS source
ON
target.delivery_id = TO_NUMBER(source.deliveryid) and
target.order_id_fk = TO_NUMBER(source.orderid) and
target.delivery_agent_id_fk = TO_NUMBER(source.deliveryagentid)
WHEN MATCHED THEN
-- Update the existing record with the latest data
UPDATE SET
delivery_status = source.deliverystatus,
estimated_time = source.estimatedtime,
customer_address_id_fk = TO_NUMBER(source.addressid),
delivery_date = TO_TIMESTAMP(source.deliverydate),
created_date = TO_TIMESTAMP(source.createddate),
modified_date = TO_TIMESTAMP(source.modifieddate),
_stg_file_name = source._stg_file_name,
_stg_file_load_ts = source._stg_file_load_ts,
_stg_file_md5 = source._stg_file_md5,
_copy_data_ts = source._copy_data_ts
WHEN NOT MATCHED THEN
-- Insert new record if no match is found
INSERT (
delivery_id,
order_id_fk,
delivery_agent_id_fk,
delivery_status,
estimated_time,
customer_address_id_fk,
delivery_date,
created_date,
modified_date,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
_copy_data_ts
)
VALUES (
TO_NUMBER(source.deliveryid),
TO_NUMBER(source.orderid),
TO_NUMBER(source.deliveryagentid),
source.deliverystatus,
source.estimatedtime,
TO_NUMBER(source.addressid),
TO_TIMESTAMP(source.deliverydate),
TO_TIMESTAMP(source.createddate),
TO_TIMESTAMP(source.modifieddate),
source._stg_file_name,
source._stg_file_load_ts,
source._stg_file_md5,
source._copy_data_ts
);
Order Entity — SQL Script

use role sysadmin;
use database sandbox;
use schema stage_sch;
use warehouse adhoc_wh;
create or replace table stage_sch.orders (
orderid text comment 'Primary Key (Source System)', -- primary key as text
customerid text comment 'Customer FK(Source System)', -- foreign key reference as text (no constraint in snowflake)
restaurantid text comment 'Restaurant FK(Source System)', -- foreign key reference as text (no constraint in snowflake)
orderdate text, -- order date as text
totalamount text, -- total amount as text (no decimal constraint)
status text, -- status as text
paymentmethod text, -- payment method as text
createddate text, -- created date as text
modifieddate text, -- modified date as text
-- audit columns with appropriate data types
_stg_file_name text,
_stg_file_load_ts timestamp,
_stg_file_md5 text,
_copy_data_ts timestamp default current_timestamp
)
comment = 'This is the order stage/raw table where data will be copied from internal stage using copy command. This is as-is data represetation from the source location. All the columns are text data type except the audit columns that are added for traceability.';
create or replace stream stage_sch.orders_stm
on table stage_sch.orders
append_only = true
comment = 'This is the append-only stream object on orders entity that only gets delta data';
list @stage_sch.csv_stg/initial/orders/orders-initial.csv;
copy into stage_sch.orders (orderid, customerid, restaurantid, orderdate, totalamount,
status, paymentmethod, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as orderid,
t.$2::text as customerid,
t.$3::text as restaurantid,
t.$4::text as orderdate,
t.$5::text as totalamount,
t.$6::text as status,
t.$7::text as paymentmethod,
t.$8::text as createddate,
t.$9::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/initial/orders/orders-initial.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
CREATE OR REPLACE TABLE CLEAN_SCH.ORDERS (
ORDER_SK NUMBER AUTOINCREMENT PRIMARY KEY comment 'Surrogate Key (EDW)', -- Auto-incremented primary key
ORDER_ID BIGINT UNIQUE comment 'Primary Key (Source System)', -- Primary key inferred as BIGINT
CUSTOMER_ID_FK BIGINT comment 'Customer FK(Source System)', -- Foreign key inferred as BIGINT
RESTAURANT_ID_FK BIGINT comment 'Restaurant FK(Source System)', -- Foreign key inferred as BIGINT
ORDER_DATE TIMESTAMP, -- Order date inferred as TIMESTAMP
TOTAL_AMOUNT DECIMAL(10, 2), -- Total amount inferred as DECIMAL with two decimal places
STATUS STRING, -- Status as STRING
PAYMENT_METHOD STRING, -- Payment method as STRING
created_dt timestamp_tz, -- record creation date
modified_dt timestamp_tz, -- last modified date, allows null if not modified
-- additional audit columns
_stg_file_name string, -- file name for audit
_stg_file_load_ts timestamp_ntz, -- file load timestamp for audit
_stg_file_md5 string, -- md5 hash for file content for audit
_copy_data_ts timestamp_ntz default current_timestamp -- timestamp when data is copied, defaults to current timestamp
)
comment = 'Order entity under clean schema with appropriate data type under clean schema layer, data is populated using merge statement from the stage layer location table. This table does not support SCD2';
-- Stream object to capture the changes.
create or replace stream CLEAN_SCH.ORDERS_stm
on table CLEAN_SCH.ORDERS
comment = 'This is the stream object on ORDERS table table to track insert, update, and delete changes';
MERGE INTO CLEAN_SCH.ORDERS AS target
USING STAGE_SCH.ORDERS_STM AS source
ON target.ORDER_ID = TRY_TO_NUMBER(source.ORDERID) -- Match based on ORDER_ID
WHEN MATCHED THEN
-- Update existing records
UPDATE SET
TOTAL_AMOUNT = TRY_TO_DECIMAL(source.TOTALAMOUNT),
STATUS = source.STATUS,
PAYMENT_METHOD = source.PAYMENTMETHOD,
MODIFIED_DT = TRY_TO_TIMESTAMP_TZ(source.MODIFIEDDATE),
_STG_FILE_NAME = source._STG_FILE_NAME,
_STG_FILE_LOAD_TS = source._STG_FILE_LOAD_TS,
_STG_FILE_MD5 = source._STG_FILE_MD5,
_COPY_DATA_TS = CURRENT_TIMESTAMP
WHEN NOT MATCHED THEN
-- Insert new records
INSERT (
ORDER_ID,
CUSTOMER_ID_FK,
RESTAURANT_ID_FK,
ORDER_DATE,
TOTAL_AMOUNT,
STATUS,
PAYMENT_METHOD,
CREATED_DT,
MODIFIED_DT,
_STG_FILE_NAME,
_STG_FILE_LOAD_TS,
_STG_FILE_MD5,
_COPY_DATA_TS
)
VALUES (
TRY_TO_NUMBER(source.ORDERID),
TRY_TO_NUMBER(source.CUSTOMERID),
TRY_TO_NUMBER(source.RESTAURANTID),
TRY_TO_TIMESTAMP(source.ORDERDATE),
TRY_TO_DECIMAL(source.TOTALAMOUNT),
source.STATUS,
source.PAYMENTMETHOD,
TRY_TO_TIMESTAMP_TZ(source.CREATEDDATE),
TRY_TO_TIMESTAMP_TZ(source.MODIFIEDDATE),
source._STG_FILE_NAME,
source._STG_FILE_LOAD_TS,
source._STG_FILE_MD5,
CURRENT_TIMESTAMP
);
-- part-2
list @stage_sch.csv_stg/delta/orders/;
copy into stage_sch.orders (orderid, customerid, restaurantid, orderdate, totalamount,
status, paymentmethod, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as orderid,
t.$2::text as customerid,
t.$3::text as restaurantid,
t.$4::text as orderdate,
t.$5::text as totalamount,
t.$6::text as status,
t.$7::text as paymentmethod,
t.$8::text as createddate,
t.$9::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/delta/orders/day-02-orders.csv t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;Order Item — SQL Script

use role sysadmin;
use database sandbox;
use schema stage_sch;
use warehouse adhoc_wh;
create or replace table stage_sch.orderitem (
orderitemid text comment 'Primary Key (Source System)', -- primary key as text
orderid text comment 'Order FK(Source System)', -- foreign key reference as text (no constraint in snowflake)
menuid text comment 'Menu FK(Source System)', -- foreign key reference as text (no constraint in snowflake)
quantity text, -- quantity as text
price text, -- price as text (no decimal constraint)
subtotal text, -- subtotal as text (no decimal constraint)
createddate text, -- created date as text
modifieddate text, -- modified date as text
-- audit columns with appropriate data types
_stg_file_name text,
_stg_file_load_ts timestamp,
_stg_file_md5 text,
_copy_data_ts timestamp default current_timestamp
)
comment = 'This is the order item stage/raw table where data will be copied from internal stage using copy command. This is as-is data represetation from the source location. All the columns are text data type except the audit columns that are added for traceability.';
create or replace stream stage_sch.orderitem_stm
on table stage_sch.orderitem
append_only = true
comment = 'This is the append-only stream object on order item table that only gets delta data';
list @stage_sch.csv_stg/initial/order-item;
copy into stage_sch.orderitem (orderitemid, orderid, menuid, quantity, price,
subtotal, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as orderitemid,
t.$2::text as orderid,
t.$3::text as menuid,
t.$4::text as quantity,
t.$5::text as price,
t.$6::text as subtotal,
t.$7::text as createddate,
t.$8::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/initial/order-items/ t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;
select * from stage_sch.orderitem;
select * from stage_sch.orderitem_stm;
CREATE OR REPLACE TABLE clean_sch.order_item (
order_item_sk NUMBER AUTOINCREMENT primary key comment 'Surrogate Key (EDW)', -- Auto-incremented unique identifier for each order item
order_item_id NUMBER NOT NULL UNIQUE comment 'Primary Key (Source System)',
order_id_fk NUMBER NOT NULL comment 'Order FK(Source System)', -- Foreign key reference for Order ID
menu_id_fk NUMBER NOT NULL comment 'Menu FK(Source System)', -- Foreign key reference for Menu ID
quantity NUMBER(10, 2), -- Quantity as a decimal number
price NUMBER(10, 2), -- Price as a decimal number
subtotal NUMBER(10, 2), -- Subtotal as a decimal number
created_dt TIMESTAMP, -- Created date of the order item
modified_dt TIMESTAMP, -- Modified date of the order item
-- Audit columns
_stg_file_name VARCHAR(255), -- File name of the staging file
_stg_file_load_ts TIMESTAMP, -- Timestamp when the file was loaded
_stg_file_md5 VARCHAR(255), -- MD5 hash of the file for integrity check
_copy_data_ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- Timestamp when data is copied into the clean layer
)
comment = 'Order item entity under clean schema with appropriate data type under clean schema layer, data is populated using merge statement from the stage layer location table. This table does not support SCD2';
create or replace stream CLEAN_SCH.order_item_stm
on table CLEAN_SCH.order_item
comment = 'This is the stream object on order_item table table to track insert, update, and delete changes';
select * from clean_sch.order_item_stm;
MERGE INTO clean_sch.order_item AS target
USING stage_sch.orderitem_stm AS source
ON
target.order_item_id = source.orderitemid and
target.order_id_fk = source.orderid and
target.menu_id_fk = source.menuid
WHEN MATCHED THEN
-- Update the existing record with new data
UPDATE SET
target.quantity = source.quantity,
target.price = source.price,
target.subtotal = source.subtotal,
target.created_dt = source.createddate,
target.modified_dt = source.modifieddate,
target._stg_file_name = source._stg_file_name,
target._stg_file_load_ts = source._stg_file_load_ts,
target._stg_file_md5 = source._stg_file_md5,
target._copy_data_ts = source._copy_data_ts
WHEN NOT MATCHED THEN
-- Insert new record if no match is found
INSERT (
order_item_id,
order_id_fk,
menu_id_fk,
quantity,
price,
subtotal,
created_dt,
modified_dt,
_stg_file_name,
_stg_file_load_ts,
_stg_file_md5,
_copy_data_ts
)
VALUES (
source.orderitemid,
source.orderid,
source.menuid,
source.quantity,
source.price,
source.subtotal,
source.createddate,
source.modifieddate,
source._stg_file_name,
source._stg_file_load_ts,
source._stg_file_md5,
CURRENT_TIMESTAMP()
);
-- part-2
list @stage_sch.csv_stg/delta/order-items/;
copy into stage_sch.orderitem (orderitemid, orderid, menuid, quantity, price,
subtotal, createddate, modifieddate,
_stg_file_name, _stg_file_load_ts, _stg_file_md5, _copy_data_ts)
from (
select
t.$1::text as orderitemid,
t.$2::text as orderid,
t.$3::text as menuid,
t.$4::text as quantity,
t.$5::text as price,
t.$6::text as subtotal,
t.$7::text as createddate,
t.$8::text as modifieddate,
metadata$filename as _stg_file_name,
metadata$file_last_modified as _stg_file_load_ts,
metadata$file_content_key as _stg_file_md5,
current_timestamp as _copy_data_ts
from @stage_sch.csv_stg/delta/order-items/ t
)
file_format = (format_name = 'stage_sch.csv_file_format')
on_error = abort_statement;Date Dimension — SQL
use role sysadmin;
use warehouse adhoc_wh;
use database sandbox;
use schema CONSUMPTION_SCH;
CREATE OR REPLACE TABLE CONSUMPTION_SCH.DATE_DIM (
DATE_DIM_HK NUMBER PRIMARY KEY comment 'Menu Dim HK (EDW)', -- Surrogate key for date dimension
CALENDAR_DATE DATE UNIQUE, -- The actual calendar date
YEAR NUMBER, -- Year
QUARTER NUMBER, -- Quarter (1-4)
MONTH NUMBER, -- Month (1-12)
WEEK NUMBER, -- Week of the year
DAY_OF_YEAR NUMBER, -- Day of the year (1-365/366)
DAY_OF_WEEK NUMBER, -- Day of the week (1-7)
DAY_OF_THE_MONTH NUMBER, -- Day of the month (1-31)
DAY_NAME STRING -- Name of the day (e.g., Monday)
)
comment = 'Date dimension table created using min of order data.';
insert into CONSUMPTION_SCH.DATE_DIM
with recursive my_date_dim_cte as
(
-- anchor clause
select
current_date() as today,
year(today) as year,
quarter(today) as quarter,
month(today) as month,
week(today) as week,
dayofyear(today) as day_of_year,
dayofweek(today) as day_of_week,
day(today) as day_of_the_month,
dayname(today) as day_name
union all
-- recursive clause
select
dateadd('day', -1, today) as today_r,
year(today_r) as year,
quarter(today_r) as quarter,
month(today_r) as month,
week(today_r) as week,
dayofyear(today_r) as day_of_year,
dayofweek(today_r) as day_of_week,
day(today_r) as day_of_the_month,
dayname(today_r) as day_name
from
my_date_dim_cte
where
today_r > (select date(min(order_date)) from clean_sch.orders)
)
select
hash(SHA1_hex(today)) as DATE_DIM_HK,
today , -- The actual calendar date
YEAR, -- Year
QUARTER, -- Quarter (1-4)
MONTH, -- Month (1-12)
WEEK, -- Week of the year
DAY_OF_YEAR, -- Day of the year (1-365/366)
DAY_OF_WEEK, -- Day of the week (1-7)
DAY_OF_THE_MONTH, -- Day of the month (1-31)
DAY_NAME
from my_date_dim_cte;Order Item Fact — SQL Scripts

use role sysadmin;
use warehouse adhoc_wh;
use database sandbox;
use schema consumption_sch;
CREATE OR REPLACE TABLE consumption_sch.order_item_fact (
order_item_fact_sk NUMBER AUTOINCREMENT comment 'Surrogate Key (EDW)', -- Surrogate key for the fact table
order_item_id NUMBER comment 'Order Item FK (Source System)', -- Natural key from the source data
order_id NUMBER comment 'Order FK (Source System)', -- Reference to the order dimension
customer_dim_key NUMBER comment 'Order FK (Source System)', -- Reference to the customer dimension
customer_address_dim_key NUMBER, -- Reference to the customer dimension
restaurant_dim_key NUMBER, -- Reference to the restaurant dimension
restaurant_location_dim_key NUMBER, -- Reference to the restaurant dimension
menu_dim_key NUMBER, -- Reference to the menu dimension
delivery_agent_dim_key NUMBER, -- Reference to the delivery agent dimension
order_date_dim_key NUMBER, -- Reference to the date dimension
quantity NUMBER, -- Measure
price NUMBER(10, 2), -- Measure
subtotal NUMBER(10, 2), -- Measure
delivery_status VARCHAR, -- Delivery information
estimated_time VARCHAR -- Delivery information
)
comment = 'The item order fact table that has item level price, quantity and other details';
MERGE INTO consumption_sch.order_item_fact AS target
USING (
SELECT
oi.Order_Item_ID AS order_item_id,
oi.Order_ID_fk AS order_id,
c.CUSTOMER_HK AS customer_dim_key,
ca.CUSTOMER_ADDRESS_HK AS customer_address_dim_key,
r.RESTAURANT_HK AS restaurant_dim_key,
rl.restaurant_location_hk as restaurant_location_dim_key,
m.Menu_Dim_HK AS menu_dim_key,
da.DELIVERY_AGENT_HK AS delivery_agent_dim_key,
dd.DATE_DIM_HK AS order_date_dim_key,
oi.Quantity::number(2) AS quantity,
oi.Price AS price,
oi.Subtotal AS subtotal,
o.PAYMENT_METHOD,
d.delivery_status AS delivery_status,
d.estimated_time AS estimated_time,
FROM
clean_sch.order_item_stm oi
JOIN
clean_sch.orders_stm o ON oi.Order_ID_fk = o.Order_ID
JOIN
clean_sch.delivery_stm d ON o.Order_ID = d.Order_ID_fk
JOIN
consumption_sch.CUSTOMER_DIM c on o.Customer_ID_fk = c.customer_id
JOIN
consumption_sch.CUSTOMER_ADDRESS_DIM ca on c.Customer_ID = ca.CUSTOMER_ID_fk
JOIN
consumption_sch.restaurant_dim r on o.Restaurant_ID_fk = r.restaurant_id
JOIN
consumption_sch.menu_dim m ON oi.MENU_ID_fk = m.menu_id
JOIN
consumption_sch.delivery_agent_dim da ON d.Delivery_Agent_ID_fk = da.delivery_agent_id
JOIN
consumption_sch.restaurant_location_dim rl on r.LOCATION_ID_FK = rl.location_id
JOIN
CONSUMPTION_SCH.DATE_DIM dd on dd.calendar_date = date(o.order_date)
) AS source_stm
ON
target.order_item_id = source_stm.order_item_id and
target.order_id = source_stm.order_id
WHEN MATCHED THEN
-- Update existing fact record
UPDATE SET
target.customer_dim_key = source_stm.customer_dim_key,
target.customer_address_dim_key = source_stm.customer_address_dim_key,
target.restaurant_dim_key = source_stm.restaurant_dim_key,
target.restaurant_location_dim_key = source_stm.restaurant_location_dim_key,
target.menu_dim_key = source_stm.menu_dim_key,
target.delivery_agent_dim_key = source_stm.delivery_agent_dim_key,
target.order_date_dim_key = source_stm.order_date_dim_key,
target.quantity = source_stm.quantity,
target.price = source_stm.price,
target.subtotal = source_stm.subtotal,
target.delivery_status = source_stm.delivery_status,
target.estimated_time = source_stm.estimated_time
WHEN NOT MATCHED THEN
-- Insert new fact record
INSERT (
order_item_id,
order_id,
customer_dim_key,
customer_address_dim_key,
restaurant_dim_key,
restaurant_location_dim_key,
menu_dim_key,
delivery_agent_dim_key,
order_date_dim_key,
quantity,
price,
subtotal,
delivery_status,
estimated_time
)
VALUES (
source_stm.order_item_id,
source_stm.order_id,
source_stm.customer_dim_key,
source_stm.customer_address_dim_key,
source_stm.restaurant_dim_key,
source_stm.restaurant_location_dim_key,
source_stm.menu_dim_key,
source_stm.delivery_agent_dim_key,
source_stm.order_date_dim_key,
source_stm.quantity,
source_stm.price,
source_stm.subtotal,
source_stm.delivery_status,
source_stm.estimated_time
);
-- start with
alter table consumption_sch.order_item_fact
add constraint fk_order_item_fact_customer_dim
foreign key (customer_dim_key)
references consumption_sch.customer_dim (customer_hk);
alter table consumption_sch.order_item_fact
add constraint fk_order_item_fact_customer_address_dim
foreign key (customer_address_dim_key)
references consumption_sch.customer_address_dim (CUSTOMER_ADDRESS_HK);
alter table consumption_sch.order_item_fact
add constraint fk_order_item_fact_restaurant_dim
foreign key (restaurant_dim_key)
references consumption_sch.restaurant_dim (restaurant_hk);
alter table consumption_sch.order_item_fact
add constraint fk_order_item_fact_restaurant_location_dim
foreign key (restaurant_location_dim_key)
references consumption_sch.restaurant_location_dim (restaurant_location_hk);
alter table consumption_sch.order_item_fact
add constraint fk_order_item_fact_menu_dim
foreign key (menu_dim_key)
references consumption_sch.menu_dim (menu_dim_hk);
alter table consumption_sch.order_item_fact
add constraint fk_order_item_fact_delivery_agent_dim
foreign key (delivery_agent_dim_key)
references consumption_sch.delivery_agent_dim (delivery_agent_hk);
alter table consumption_sch.order_item_fact
add constraint fk_order_item_fact_delivery_date_dim
foreign key (order_date_dim_key)
references consumption_sch.date_dim (date_dim_hk);Final View — SQL Scripts
use role sysadmin;
use warehouse adhoc_wh;
use database sandbox;
use schema consumption_sch;
select * from consumption_sch.order_item_fact limit 100;
create or replace view consumption_sch.vw_yearly_revenue_kpis as
select
d.year as year, -- fetch year from date_dim
sum(fact.subtotal) as total_revenue,
count(distinct fact.order_id) as total_orders,
round(sum(fact.subtotal) / count(distinct fact.order_id), 2) as avg_revenue_per_order,
round(sum(fact.subtotal) / count(fact.order_item_id), 2) as avg_revenue_per_item,
max(fact.subtotal) as max_order_value
from
consumption_sch.order_item_fact fact
join
consumption_sch.date_dim d
on
fact.order_date_dim_key = d.date_dim_hk -- join fact table with date_dim table
where DELIVERY_STATUS = 'Delivered'
group by
d.year
order by
d.year;
CREATE OR REPLACE VIEW consumption_sch.vw_monthly_revenue_kpis AS
SELECT
d.YEAR AS year, -- Fetch year from DATE_DIM
d.MONTH AS month, -- Fetch month from DATE_DIM
SUM(fact.subtotal) AS total_revenue,
COUNT(DISTINCT fact.order_id) AS total_orders,
ROUND(SUM(fact.subtotal) / COUNT(DISTINCT fact.order_id), 2) AS avg_revenue_per_order,
ROUND(SUM(fact.subtotal) / COUNT(fact.order_item_id), 2) AS avg_revenue_per_item,
MAX(fact.subtotal) AS max_order_value
FROM
consumption_sch.order_item_fact fact
JOIN
consumption_sch.DATE_DIM d
ON
fact.order_date_dim_key = d.DATE_DIM_HK -- Join fact table with DATE_DIM table
where DELIVERY_STATUS = 'Delivered'
GROUP BY
d.YEAR, d.MONTH
ORDER BY
d.YEAR, d.MONTH;
CREATE OR REPLACE VIEW consumption_sch.vw_daily_revenue_kpis AS
SELECT
d.YEAR AS year, -- Fetch year from DATE_DIM
d.MONTH AS month, -- Fetch month from DATE_DIM
d.DAY_OF_THE_MONTH AS day, -- Fetch day from DATE_DIM
SUM(fact.subtotal) AS total_revenue,
COUNT(DISTINCT fact.order_id) AS total_orders,
ROUND(SUM(fact.subtotal) / COUNT(DISTINCT fact.order_id), 2) AS avg_revenue_per_order,
ROUND(SUM(fact.subtotal) / COUNT(fact.order_item_id), 2) AS avg_revenue_per_item,
MAX(fact.subtotal) AS max_order_value
FROM
consumption_sch.order_item_fact fact
JOIN
consumption_sch.DATE_DIM d
ON
fact.order_date_dim_key = d.DATE_DIM_HK -- Join fact table with DATE_DIM table
where DELIVERY_STATUS = 'Delivered'
GROUP BY
d.YEAR, d.MONTH, d.DAY_OF_THE_MONTH -- Group by year, month, and day
ORDER BY
d.YEAR, d.MONTH, d.DAY_OF_THE_MONTH; -- Order by year, month, and day
CREATE OR REPLACE VIEW consumption_sch.vw_day_revenue_kpis AS
SELECT
d.YEAR AS year, -- Fetch year from DATE_DIM
d.MONTH AS month, -- Fetch month from DATE_DIM
d.DAY_NAME AS DAY_NAME, -- Fetch day from DATE_DIM-DAY_NAME
SUM(fact.subtotal) AS total_revenue,
COUNT(DISTINCT fact.order_id) AS total_orders,
ROUND(SUM(fact.subtotal) / COUNT(DISTINCT fact.order_id), 2) AS avg_revenue_per_order,
ROUND(SUM(fact.subtotal) / COUNT(fact.order_item_id), 2) AS avg_revenue_per_item,
MAX(fact.subtotal) AS max_order_value
FROM
consumption_sch.order_item_fact fact
JOIN
consumption_sch.DATE_DIM d
ON
fact.order_date_dim_key = d.DATE_DIM_HK -- Join fact table with DATE_DIM table
GROUP BY
d.YEAR, d.MONTH, d.DAY_NAME -- Group by year, month, and day
ORDER BY
d.YEAR, d.MONTH, d.DAY_NAME; -- Order by year, month, and day
CREATE OR REPLACE VIEW consumption_sch.vw_monthly_revenue_by_restaurant AS
SELECT
d.YEAR AS year, -- Fetch year from DATE_DIM
d.MONTH AS month, -- Fetch month from DATE_DIM
fact.DELIVERY_STATUS,
r.name as restaurant_name,
SUM(fact.subtotal) AS total_revenue,
COUNT(DISTINCT fact.order_id) AS total_orders,
ROUND(SUM(fact.subtotal) / COUNT(DISTINCT fact.order_id), 2) AS avg_revenue_per_order,
ROUND(SUM(fact.subtotal) / COUNT(fact.order_item_id), 2) AS avg_revenue_per_item,
MAX(fact.subtotal) AS max_order_value
FROM
consumption_sch.order_item_fact fact
JOIN
consumption_sch.DATE_DIM d
ON
fact.order_date_dim_key = d.DATE_DIM_HK
JOIN
consumption_sch.restaurant_dim r
ON
fact.restaurant_dim_key = r.RESTAURANT_HK
GROUP BY
d.YEAR, d.MONTH,fact.DELIVERY_STATUS,restaurant_name
ORDER BY
d.YEAR, d.MONTH;Streamlit Code
# Import python packages
import streamlit as st
import pandas as pd
import altair as alt
from snowflake.snowpark.context import get_active_session
# App Title
st.title("Revenue Dashboard")
# Get the current credentials
session = get_active_session()
def format_revenue(revenue):
#return f"₹{revenue / 1_000_000:.1f}M"
return f"₹{revenue:.1f}"
# Function to alternate row colors
def highlight_rows(row):
color = '#f2f2f2' if row.name % 2 == 0 else 'white' # Alternate rows
return ['background-color: {}'.format(color)] * len(row)
# Function to fetch KPI data from Snowflake
def fetch_kpi_data():
query = """
SELECT
year,
total_revenue,
total_orders,
avg_revenue_per_order,
avg_revenue_per_item,
max_order_value
FROM sandbox.consumption_sch.vw_yearly_revenue_kpis
ORDER BY year;
"""
return session.sql(query).collect()
#TO_CHAR(TO_DATE(month::text, 'MM'), 'Mon') AS month_abbr, -- Converts month number to abbreviated month name
def fetch_monthly_kpi_data(year):
query = f"""
SELECT
month::number(2) as month,
total_revenue::NUMBER(10) AS TOTAL_REVENUE
FROM
sandbox.consumption_sch.vw_monthly_revenue_kpis
WHERE year = {year}
ORDER BY month;
"""
return session.sql(query).collect()
def fetch_unique_months(year):
query = f"""
SELECT
DISTINCT MONTH FROM
sandbox.consumption_sch.vw_monthly_revenue_by_restaurant
WHERE YEAR = {year}
ORDER BY MONTH;
"""
return session.sql(query).collect()
def fetch_top_restaurants(year, month):
query = f"""
SELECT
restaurant_name,
total_revenue,
total_orders,
avg_revenue_per_order,
avg_revenue_per_item,
max_order_value
FROM
sandbox.consumption_sch.vw_monthly_revenue_by_restaurant
WHERE
YEAR = {year}
AND MONTH = {month}
ORDER BY
total_revenue DESC
LIMIT 10;
"""
return session.sql(query).collect()
# Function to convert Snowpark DataFrame to Pandas DataFrame
def snowpark_to_pandas(snowpark_df):
return pd.DataFrame(
snowpark_df,
columns=[
'Restaurant Name',
'Total Revenue (₹)',
'Total Orders',
'Avg Revenue per Order (₹)',
'Avg Revenue per Item (₹)',
'Max Order Value (₹)'
]
)
# Fetch data
sf_df = fetch_kpi_data()
df = pd.DataFrame(
sf_df,
columns=['YEAR','TOTAL_REVENUE','TOTAL_ORDERS','AVG_REVENUE_PER_ORDER','AVG_REVENUE_PER_ITEM','MAX_ORDER_VALUE']
)
# Aggregate Metrics for All Years
#st.subheader("Aggregate KPIs: Overall Performance")
col1, col2, col3 = st.columns(3)
with col1:
st.metric("Total Revenue (All Years)", format_revenue(df['TOTAL_REVENUE'].sum()))
with col2:
st.metric("Total Orders (All Years)", f"{df['TOTAL_ORDERS'].sum():,}")
with col3:
st.metric("Max Order Value (Overall)", f"₹{df['MAX_ORDER_VALUE'].max():,.0f}")
st.divider()
# Year Selection Box
years = df["YEAR"].unique()
default_year = max(years) # Select the most recent year by default
selected_year = st.selectbox("Select Year", sorted(years), index=list(years).index(default_year))
# Filter data for selected year
year_data = df[df["YEAR"] == selected_year]
total_revenue = year_data["TOTAL_REVENUE"].iloc[0]
total_orders = year_data["TOTAL_ORDERS"].iloc[0]
avg_revenue_per_order = year_data["AVG_REVENUE_PER_ORDER"].iloc[0]
avg_revenue_per_item = year_data["AVG_REVENUE_PER_ITEM"].iloc[0]
max_order_value = year_data["MAX_ORDER_VALUE"].iloc[0]
# Get previous year data
previous_year = selected_year - 1
previous_year_data = df[df["YEAR"] == previous_year]
# If previous year data exists, calculate differences
if not previous_year_data.empty:
prev_total_revenue = previous_year_data["TOTAL_REVENUE"].iloc[0]
prev_total_orders = previous_year_data["TOTAL_ORDERS"].iloc[0]
prev_avg_revenue_per_order = previous_year_data["AVG_REVENUE_PER_ORDER"].iloc[0]
prev_avg_revenue_per_item = previous_year_data["AVG_REVENUE_PER_ITEM"].iloc[0]
prev_max_order_value = previous_year_data["MAX_ORDER_VALUE"].iloc[0]
# Calculate differences
revenue_diff = total_revenue - prev_total_revenue
orders_diff = total_orders - prev_total_orders
avg_rev_order_diff = avg_revenue_per_order - prev_avg_revenue_per_order
avg_rev_item_diff = avg_revenue_per_item - prev_avg_revenue_per_item
max_order_diff = max_order_value - prev_max_order_value
else:
# If previous year data is not found, set differences to None or zero
revenue_diff = orders_diff = avg_rev_order_diff = avg_rev_item_diff = max_order_diff = None
# Display Metrics for Selected Year with Comparison to Previous Year
# st.subheader(f"KPI Scorecard for {selected_year}")
col1, col2, col3 = st.columns(3)
with col1:
st.metric(
"Total Revenue",
format_revenue(total_revenue),
delta=f"₹{revenue_diff:.1f}" if revenue_diff is not None else None
)
st.metric("Total Orders", f"{total_orders:,}", delta=f"{orders_diff:,}" if orders_diff is not None else None)
#st.metric("Total Revenue", f"₹{total_revenue:,.0f}", delta=f"₹{revenue_diff:,.0f}" if revenue_diff is not None else None)
#st.metric("Total Orders", f"{total_orders:,}", delta=f"{orders_diff:,}" if orders_diff is not None else None)
with col2:
st.metric("Avg Revenue per Order", f"₹{avg_revenue_per_order:,.0f}", delta=f"₹{avg_rev_order_diff:,.0f}" if avg_rev_order_diff is not None else None)
st.metric("Avg Revenue per Item", f"₹{avg_revenue_per_item:,.0f}", delta=f"₹{avg_rev_item_diff:,.0f}" if avg_rev_item_diff is not None else None)
with col3:
st.metric("Max Order Value", f"₹{max_order_value:,.0f}", delta=f"₹{max_order_diff:,.0f}" if max_order_diff is not None else None)
st.divider()
# -----------------------------------------
# Fetch and prepare data
month_sf_df = fetch_monthly_kpi_data(selected_year)
month_df = pd.DataFrame(
month_sf_df,
columns=['Month', 'Total Monthly Revenue']
)
# Map numeric months to abbreviated month names
month_mapping = {
1: 'Jan', 2: 'Feb', 3: 'Mar', 4: 'Apr',
5: 'May', 6: 'Jun', 7: 'Jul', 8: 'Aug',
9: 'Sep', 10: 'Oct', 11: 'Nov', 12: 'Dec'
}
month_df['Month'] = month_df['Month'].map(month_mapping)
# Ensure months are in the correct chronological order
month_df['Month'] = pd.Categorical(
month_df['Month'],
categories=['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'],
ordered=True
)
month_df = month_df.sort_values('Month') # Sort by chronological month order
# Convert revenue to millions
month_df['Total Monthly Revenue'] = month_df['Total Monthly Revenue']
# Plot Monthly Revenue Trend using Bar Chart
st.subheader(f"{selected_year} - Monthly Revenue Trend")
# Create the Altair Bar Chart with Custom Color
bar_chart = alt.Chart(month_df).mark_bar(color="#ff5200").encode(
x=alt.X('Month', sort='ascending', title='Month'),
y=alt.Y('Total Monthly Revenue', title='Revenue (₹)')
).properties(
width=700,
height=400
)
# Display the chart in Streamlit
st.altair_chart(bar_chart, use_container_width=True)
# Add a Trending Chart using Altair
st.subheader(f"{selected_year} - Monthly Revenue Trend")
trend_chart = alt.Chart(month_df).mark_line(color="#ff5200", point=alt.OverlayMarkDef(color="#ff5200")).encode(
x=alt.X('Month', sort='ascending', title='Month'),
y=alt.Y('Total Monthly Revenue', title='Revenue (₹)', scale=alt.Scale(domain=[0, month_df['Total Monthly Revenue'].max()])),
tooltip=[
alt.Tooltip('Month', title='Month'),
alt.Tooltip('Total Monthly Revenue', title='Revenue (₹M)', format='.2f') # Format to 2 decimal places
]
).properties(
width=700,
height=400
).configure_point(
size=60
)
st.altair_chart(trend_chart, use_container_width=True)
# Month Selection based on the selected year
if selected_year:
#get the unique months
month_sf_df = fetch_unique_months(selected_year)
print(month_sf_df)
#convert into df
month_df = pd.DataFrame(
month_sf_df,
columns=['MONTH']
)
print(month_df)
# Year Selection Box
months = month_df["MONTH"].unique()
default_month = max(months) # Select the most recent year by default
selected_month = st.selectbox(f"Select Month For {selected_year}", sorted(months), index=list(months).index(default_month))
# Fetch and Display Data
if selected_month:
st.subheader(f"Top 10 Restaurants for {selected_month}/{selected_year}")
top_restaurants = fetch_top_restaurants(selected_year, selected_month)
if top_restaurants:
top_restaurants_df = snowpark_to_pandas(top_restaurants)
# Remove index from DataFrame by resetting it and dropping the index column
#top_restaurants_df_reset = top_restaurants_df.reset_index(drop=True)
# Display the DataFrame without index
#st.dataframe(top_restaurants_df_reset)
#st.dataframe(top_restaurants_df)
# Apply the alternate color style
styled_df = top_restaurants_df.style.apply(highlight_rows, axis=1)
# Display the styled DataFrame
st.dataframe(styled_df, hide_index= True)
else:
st.warning("No data found for the selected year and month.")
